
小巧、快速、可靠。
任選三項。
任選三項。
FTS3 和 FTS4 是 SQLite 虛擬表格模組,允許使用者對一組文件執行全文搜尋。描述全文搜尋最常見(且有效)的方式是「Google、Yahoo 和 Bing 對放置在萬維網上的文件所做的處理」。使用者輸入一個術語或一系列術語,可能透過二元運算子連接或組合成一個片語,而全文查詢系統會找出最符合這些術語的文檔集,並考量使用者指定的運算子與組合。本文說明 FTS3 和 FTS4 的部署和使用方式。
FTS1 和 FTS2 是 SQLite 的過時全文搜尋模組。這些較舊的模組有已知問題,應避免使用。原始 FTS3 程式碼的部分內容是由 Google 的 Scott Hess 提供給 SQLite 專案。它現在作為 SQLite 的一部分進行開發和維護。
FTS3 和 FTS4 擴充模組允許使用者建立具有內建全文索引的特殊表格(以下簡稱「FTS 表格」)。全文索引允許使用者有效率地查詢資料庫,找出包含一個或多個字詞(以下簡稱「標記」)的所有列,即使表格包含許多大型文件。
例如,如果「Enron 電子郵件資料集」中的 517430 份文件都插入 FTS 表格和使用下列 SQL 腳本建立的普通 SQLite 表格
CREATE VIRTUAL TABLE enrondata1 USING fts3(content TEXT); /* FTS3 table */ CREATE TABLE enrondata2(content TEXT); /* Ordinary table */
則可執行下列兩個查詢中的任一個,以找出資料庫中包含「linux」一詞的文件數量 (351)。使用一個桌上型電腦硬體組態,FTS3 表格上的查詢約在 0.03 秒內傳回,而查詢普通表格則需要 22.5 秒。
SELECT count(*) FROM enrondata1 WHERE content MATCH 'linux'; /* 0.03 seconds */ SELECT count(*) FROM enrondata2 WHERE content LIKE '%linux%'; /* 22.5 seconds */
當然,上述兩個查詢並不完全等效。例如,LIKE 查詢會比對包含「linuxophobe」或「EnterpriseLinux」等字詞的列(碰巧的是,Enron 電子郵件資料集並未實際包含任何此類字詞),而 FTS3 表格上的 MATCH 查詢只會選取包含「linux」作為離散記號的列。這兩個搜尋都不區分大小寫。FTS3 表格在磁碟上會耗用約 2006 MB,而普通表格則僅耗用 1453 MB。使用與執行上述 SELECT 查詢相同的硬體組態,FTS3 表格僅需不到 31 分鐘即可填入,而普通表格則需要 25 分鐘。
FTS3 和 FTS4 幾乎相同。它們共用大部分程式碼,而且其介面相同。差異如下
FTS4 包含查詢效能最佳化,可能會大幅改善包含極為常見字詞(存在於表格列的大量百分比中)的全文查詢效能。
FTS4 支援一些額外的選項,可用於 matchinfo() 函數。
由於 FTS4 表格會在兩個新的 影子表格 中儲存額外的磁碟資訊,以支援效能最佳化和額外的 matchinfo() 選項,因此 FTS4 表格可能會耗用比使用 FTS3 建立的等效表格更多的磁碟空間。通常,其額外負擔為 1-2% 或更少,但如果儲存在 FTS 表格中的文件非常小,則可能會高達 10%。可以透過指定指令 "matchinfo=fts3" 作為 FTS4 表格宣告的一部分來減少額外負擔,但這會犧牲一些額外支援的 matchinfo() 選項。
FTS4 提供掛鉤(壓縮和解壓縮 選項),允許資料以壓縮形式儲存,減少磁碟使用量和 I/O。
FTS4 是 FTS3 的強化版本。FTS3 自 SQLite 版本 3.5.0(2007-09-04)以來一直可用。FTS4 的強化功能已新增至 SQLite 版本 3.7.4(2010-12-07)。
您應該在應用程式中使用哪個模組,FTS3 還是 FTS4?FTS4 有時會比 FTS3 快很多,甚至快好幾個數量級,具體取決於查詢,儘管在一般情況下,這兩個模組的效能類似。FTS4 還提供增強的 matchinfo() 輸出,這在對 MATCH 操作的結果進行排名時很有用。另一方面,在沒有 matchinfo=fts3 指令的情況下,FTS4 所需的磁碟空間比 FTS3 稍多,儘管在多數情況下只多百分之二。
對於較新的應用程式,建議使用 FTS4;儘管如果與舊版 SQLite 的相容性很重要,那麼 FTS3 通常也能發揮同樣的作用。
與其他虛擬表格類型一樣,新的 FTS 表格是使用 CREATE VIRTUAL TABLE 陳述式建立的。模組名稱位於 USING 關鍵字之後,為「fts3」或「fts4」。虛擬表格模組引數可以留空,這樣會建立一個具有單一使用者定義欄位(名為「content」)的 FTS 表格。或者,可以傳遞逗號分隔的欄位名稱清單給模組引數。
如果在 CREATE VIRTUAL TABLE 陳述式中明確提供 FTS 表格的欄位名稱,則可以選擇為每個欄位指定資料類型名稱。這純粹是語法糖,提供的類型名稱不會被 FTS 或 SQLite 核心用於任何目的。這也適用於與 FTS 欄位名稱一起指定的任何約束 - 它們會被解析,但不會被系統以任何方式使用或記錄。
-- Create an FTS table named "data" with one column - "content": CREATE VIRTUAL TABLE data USING fts3(); -- Create an FTS table named "pages" with three columns: CREATE VIRTUAL TABLE pages USING fts4(title, keywords, body); -- Create an FTS table named "mail" with two columns. Datatypes -- and column constraints are specified along with each column. These -- are completely ignored by FTS and SQLite. CREATE VIRTUAL TABLE mail USING fts3( subject VARCHAR(256) NOT NULL, body TEXT CHECK(length(body)<10240) );
除了資料欄位清單外,傳遞給 CREATE VIRTUAL TABLE 陳述式用於建立 FTS 資料表的模組參數,可用於指定 分詞器。這可透過指定「tokenize=<分詞器名稱> <分詞器參數>」格式的字串來完成,取代資料欄位名稱,其中 <分詞器名稱> 是要使用的分詞器名稱,而 <分詞器參數> 是傳遞給分詞器實作的空白分隔限定詞的選用清單。分詞器規格可放置於資料欄位清單中的任何位置,但每個 CREATE VIRTUAL TABLE 陳述式最多只允許一個分詞器宣告。請參閱 下方 以取得使用(以及必要時實作)分詞器的詳細說明。
-- Create an FTS table named "papers" with two columns that uses -- the tokenizer "porter". CREATE VIRTUAL TABLE papers USING fts3(author, document, tokenize=porter); -- Create an FTS table with a single column - "content" - that uses -- the "simple" tokenizer. CREATE VIRTUAL TABLE data USING fts4(tokenize=simple); -- Create an FTS table with two columns that uses the "icu" tokenizer. -- The qualifier "en_AU" is passed to the tokenizer implementation CREATE VIRTUAL TABLE names USING fts3(a, b, tokenize=icu en_AU);
FTS 資料表可以使用一般 DROP TABLE 陳述式從資料庫中刪除。例如
-- Create, then immediately drop, an FTS4 table. CREATE VIRTUAL TABLE data USING fts4(); DROP TABLE data;
FTS 資料表的填入方式與一般 SQLite 資料表相同,使用 INSERT、UPDATE 和 DELETE 陳述式。
除了使用者命名的資料欄位(或在 CREATE VIRTUAL TABLE 陳述式中未指定模組參數時為「內容」資料欄位)外,每個 FTS 資料表都有「rowid」資料欄位。FTS 資料表的 rowid 行為方式與一般 SQLite 資料表的 rowid 資料欄位相同,但如果資料庫使用 VACUUM 指令重新建置,儲存在 FTS 資料表 rowid 資料欄位中的值會保持不變。對於 FTS 資料表,除了常用的「rowid」、「oid」和「_oid_」識別碼外,還允許「docid」作為別名。嘗試插入或更新已存在於資料表中的 docid 值的列會產生錯誤,就像一般 SQLite 資料表一樣。
「docid」與 SQLite 行 ID 欄位的正常別名之間還有另一個細微的差異。通常,如果 INSERT 或 UPDATE 陳述式將離散值指定給兩個或以上的行 ID 欄位別名,SQLite 會將 INSERT 或 UPDATE 陳述式中指定的這些值最右邊的值寫入資料庫。但是,在插入或更新 FTS 表格時,將非 NULL 值指定給「docid」和一個或多個 SQLite 行 ID 別名會被視為錯誤。請參閱下方範例。
-- Create an FTS table
CREATE VIRTUAL TABLE pages USING fts4(title, body);
-- Insert a row with a specific docid value.
INSERT INTO pages(docid, title, body) VALUES(53, 'Home Page', 'SQLite is a software...');
-- Insert a row and allow FTS to assign a docid value using the same algorithm as
-- SQLite uses for ordinary tables. In this case the new docid will be 54,
-- one greater than the largest docid currently present in the table.
INSERT INTO pages(title, body) VALUES('Download', 'All SQLite source code...');
-- Change the title of the row just inserted.
UPDATE pages SET title = 'Download SQLite' WHERE rowid = 54;
-- Delete the entire table contents.
DELETE FROM pages;
-- The following is an error. It is not possible to assign non-NULL values to both
-- the rowid and docid columns of an FTS table.
INSERT INTO pages(rowid, docid, title, body) VALUES(1, 2, 'A title', 'A document body');
為了支援全文查詢,FTS 會維護一個反向索引,將資料集中出現的每個獨特術語或字詞對應到它在表格內容中出現的位置。對於好奇的人來說,下方會完整說明用於在資料庫檔案中儲存此索引的資料結構。此資料結構的一個特點是,資料庫隨時可能不只包含一個索引 B 樹,而是多個不同的 B 樹,這些 B 樹會在插入、更新和刪除列時逐步合併。此技術會在寫入 FTS 表格時提升效能,但會對使用索引的全文查詢造成一些負擔。評估特殊「最佳化」指令,即「INSERT INTO <fts-table>(<fts-table>) VALUES('optimize')」格式的 SQL 陳述式,會導致 FTS 將所有現有的索引 B 樹合併成一個包含整個索引的大型 B 樹。這可能是一個昂貴的操作,但可能會加速未來的查詢。
例如,要最佳化名為「docs」的 FTS 表格的全文索引
-- Optimize the internal structure of FTS table "docs".
INSERT INTO docs(docs) VALUES('optimize');
上述陳述式對某些人來說可能在語法上看起來不正確。請參閱說明簡單 fts 查詢的章節以取得說明。
還有一個已棄用的方法,可以使用 SELECT 陳述式呼叫最佳化操作。新的程式碼應該使用類似於上述 INSERT 的陳述式來最佳化 FTS 結構。
與所有其他 SQLite 資料表一樣,虛擬或其他,資料會使用 SELECT 陳述句從 FTS 資料表中擷取。
FTS 資料表可以使用兩種不同形式的 SELECT 陳述句有效率地查詢
依 rowid 查詢。如果 SELECT 陳述句的 WHERE 子句包含「rowid = ?」形式的子句,其中 ? 是 SQL 表達式,FTS 能夠直接使用等同於 SQLite INTEGER PRIMARY KEY 索引的方式擷取要求的列。
全文查詢。如果 SELECT 陳述句的 WHERE 子句包含「<column> MATCH ?」形式的子句,FTS 能夠使用內建全文索引將搜尋限制在與 MATCH 子句右側運算元指定之全文查詢字串相符的文件。
如果無法使用這兩種查詢策略,FTS 資料表上的所有查詢都會使用整個資料表的線性掃描來實作。如果資料表包含大量資料,這可能是一種不切實際的方法(本頁面的第一個範例顯示,使用現代電腦進行 1.5 GB 資料的線性掃描大約需要 30 秒)。
-- The examples in this block assume the following FTS table: CREATE VIRTUAL TABLE mail USING fts3(subject, body); SELECT * FROM mail WHERE rowid = 15; -- Fast. Rowid lookup. SELECT * FROM mail WHERE body MATCH 'sqlite'; -- Fast. Full-text query. SELECT * FROM mail WHERE mail MATCH 'search'; -- Fast. Full-text query. SELECT * FROM mail WHERE rowid BETWEEN 15 AND 20; -- Fast. Rowid lookup. SELECT * FROM mail WHERE subject = 'database'; -- Slow. Linear scan. SELECT * FROM mail WHERE subject MATCH 'database'; -- Fast. Full-text query.
在以上所有全文查詢中,MATCH 運算元的右側運算元是包含單一詞彙的字串。在這種情況下,MATCH 表達式會對包含指定字詞一個或多個實例的所有文件評估為 true(「sqlite」、「search」或「database」,視您查看哪個範例而定)。將單一詞彙指定為 MATCH 運算元的右側運算元會產生最簡單且最常見的全文查詢類型。但是,可以進行更複雜的查詢,包括片語搜尋、詞彙前綴搜尋和搜尋包含在彼此定義距離內詞彙組合的文件。全文索引可以查詢的不同方式如下所述。
通常,全文查詢不區分大小寫。但是,這取決於 FTS 表格查詢所使用的特定 分詞器。有關詳細資訊,請參閱 分詞器 部分。
上述段落指出,MATCH 運算子以簡單術語作為右手運算元,會對包含指定術語的所有文件評估為 true。在此情況下,「文件」可能指儲存在 FTS 表格列中的資料,或單一列中的內容,具體取決於用作 MATCH 運算子左手運算元的識別碼。如果指定為 MATCH 運算子左手運算元的識別碼是 FTS 表格欄位名稱,則搜尋詞必須包含在指定欄位中儲存的值。但是,如果識別碼是 FTS 表格 本身的名稱,則 MATCH 運算子會對 FTS 表格的每一列評估為 true,因為任何欄位都包含搜尋詞。下列範例說明這一點
-- Example schema CREATE VIRTUAL TABLE mail USING fts3(subject, body); -- Example table population INSERT INTO mail(docid, subject, body) VALUES(1, 'software feedback', 'found it too slow'); INSERT INTO mail(docid, subject, body) VALUES(2, 'software feedback', 'no feedback'); INSERT INTO mail(docid, subject, body) VALUES(3, 'slow lunch order', 'was a software problem'); -- Example queries SELECT * FROM mail WHERE subject MATCH 'software'; -- Selects rows 1 and 2 SELECT * FROM mail WHERE body MATCH 'feedback'; -- Selects row 2 SELECT * FROM mail WHERE mail MATCH 'software'; -- Selects rows 1, 2 and 3 SELECT * FROM mail WHERE mail MATCH 'slow'; -- Selects rows 1 and 3
乍看之下,上述範例中的最後兩個全文查詢似乎語法不正確,因為表格名稱(「mail」)用作 SQL 表達式。之所以可以接受,是因為每個 FTS 表格實際上都有 HIDDEN 欄位,其名稱與表格本身相同(在本例中為「mail」)。儲存在此欄位中的值對應用程式沒有意義,但可用作 MATCH 運算子的左手運算元。此特殊欄位也可以傳遞為 FTS 輔助函數 的引數。
下列範例說明上述內容。表達式「docs」、「docs.docs」和「main.docs.docs」都指欄位「docs」。但是,表達式「main.docs」不指任何欄位。它可用於指表格,但表格名稱不允許在下面使用的語境中使用。
-- Example schema CREATE VIRTUAL TABLE docs USING fts4(content); -- Example queries SELECT * FROM docs WHERE docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE docs.docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE main.docs.docs MATCH 'sqlite'; -- OK. SELECT * FROM docs WHERE main.docs MATCH 'sqlite'; -- Error.
從使用者的觀點來看,FTS 表格在許多方面類似於一般的 SQLite 表格。資料可以透過 INSERT、UPDATE 和 DELETE 指令新增至、修改和從 FTS 表格中移除,就像在一般表格中一樣。類似地,SELECT 指令可用於查詢資料。下列清單摘要了 FTS 和一般表格之間的差異
與所有虛擬表格類型一樣,無法建立附加至 FTS 表格的索引或觸發器。也無法使用 ALTER TABLE 指令新增額外的欄位至 FTS 表格(儘管可以使用 ALTER TABLE 來重新命名 FTS 表格)。
在用於建立 FTS 表格的「CREATE VIRTUAL TABLE」陳述式中指定的資料類型將完全被忽略。所有插入至 FTS 表格欄位(特殊 rowid 欄位除外)的值,並非套用一般類型 相似性 的規則,而是在儲存前轉換為 TEXT 類型。
FTS 表格允許使用特殊別名「docid」來參考所有 虛擬表格 支援的 rowid 欄位。
基於內建全文索引的查詢支援 FTS MATCH 運算子。
提供 FTS 輔助函式 snippet()、offsets() 和 matchinfo() 來支援全文查詢。
每個 FTS 表格都有 隱藏欄位,其名稱與表格本身相同。隱藏欄位中包含的每個列值都是一個 blob,僅可用作 MATCH 運算子的左運算元,或作為 FTS 輔助函式 最左邊的引數。
雖然 FTS3 和 FTS4 都包含在 SQLite 核心原始碼中,但它們並未預設啟用。若要建立已啟用 FTS 功能的 SQLite,請在編譯時定義預處理器巨集 SQLITE_ENABLE_FTS3。新的應用程式也應該定義 SQLITE_ENABLE_FTS3_PARENTHESIS 巨集,以啟用 加強的查詢語法 (請見下方)。通常,這會透過將下列兩個開關新增至編譯器命令列來完成
-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS
請注意,啟用 FTS3 也會讓 FTS4 可用。沒有獨立的 SQLITE_ENABLE_FTS4 編譯時間選項。SQLite 的建置不是同時支援 FTS3 和 FTS4,就是都不支援。
如果使用合併自動組態建置系統,在執行「組態」指令碼時設定 CPPFLAGS 環境變數是設定這些巨集的簡便方式。例如,下列命令
CPPFLAGS="-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS" ./configure <configure options>
其中<組態選項>是通常傳遞給組態指令碼的選項 (如有)。
由於 FTS3 和 FTS4 是虛擬表格,SQLITE_ENABLE_FTS3 編譯時間選項與 SQLITE_OMIT_VIRTUALTABLE 選項不相容。
如果 SQLite 的建置不包含 FTS 模組,則任何嘗試準備 SQL 陳述式以建立 FTS3 或 FTS4 表格,或以任何方式刪除或存取現有的 FTS 表格都將失敗。傳回的錯誤訊息將類似於「沒有此模組:ftsN」(其中 N 為 3 或 4)。
如果 ICU 函式庫 的 C 版本可用,則 FTS 也可能在定義 SQLITE_ENABLE_ICU 預處理器巨集的情況下編譯。使用此巨集編譯會啟用 FTS 分詞器,該分詞器使用 ICU 函式庫,根據指定語言和地區設定的慣例將文件分割為詞彙 (字詞)。
-DSQLITE_ENABLE_ICU
FTS 表格最實用的功能,就是可以使用內建全文索引執行的查詢。全文查詢是透過指定 WHERE 子句中 SELECT 陳述式的「<column> MATCH <全文查詢表達式>」格式子句來執行,從 FTS 表格中讀取資料。簡單 FTS 查詢會傳回包含特定詞彙的所有文件,如上所述。在該討論中,MATCH 運算式的右手運算元假設為包含單一詞彙的字串。本節說明 FTS 表格支援的更複雜查詢類型,以及如何透過指定更複雜的查詢表達式作為 MATCH 運算式的右手運算元來使用這些類型。
FTS 表格支援三種基本查詢類型
符號或符號字首查詢。可以對 FTS 表格執行查詢,以找出包含特定詞彙(如上所述的簡單案例)的所有文件,或找出包含具有特定字首的詞彙的所有文件。正如我們所見,特定詞彙的查詢表達式就是詞彙本身。用於搜尋詞彙字首的查詢表達式是字首本身,後面加上「*」字元。例如
-- Virtual table declaration CREATE VIRTUAL TABLE docs USING fts3(title, body); -- Query for all documents containing the term "linux": SELECT * FROM docs WHERE docs MATCH 'linux'; -- Query for all documents containing a term with the prefix "lin". This will match -- all documents that contain "linux", but also those that contain terms "linear", --"linker", "linguistic" and so on. SELECT * FROM docs WHERE docs MATCH 'lin*';
通常,會將令牌或令牌前綴查詢與指定為 MATCH 運算子左側的 FTS 表格欄位進行比對。或者,如果指定與 FTS 表格本身同名的特殊欄位,則會與所有欄位進行比對。這可以用在基本詞彙查詢之前指定冒號「:」字元後面的欄位名稱來覆寫。冒號「:」與要查詢的詞彙之間可以有空格,但欄位名稱與冒號「:」字元之間不能有空格。例如
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "problems" appears in either the title
-- or body of the document.
SELECT * FROM docs WHERE docs MATCH 'title:linux problems';
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "driver" appears in the body of the document
-- ("driver" may also appear in the title, but this alone will not satisfy the
-- query criteria).
SELECT * FROM docs WHERE body MATCH 'title:linux driver';
如果 FTS 表格是 FTS4 表格(而非 FTS3),令牌也可以加上「^」字元為前綴。在此情況下,為了比對,令牌必須出現在比對列的任何欄位中的第一個令牌。範例
-- All documents for which "linux" is the first token of at least one -- column. SELECT * FROM docs WHERE docs MATCH '^linux'; -- All documents for which the first token in column "title" begins with "lin". SELECT * FROM docs WHERE body MATCH 'title: ^lin*';
片語查詢。片語查詢是一種查詢,用於擷取包含一組指定的詞彙或詞彙前綴(依序且中間沒有其他令牌)的所有文件。片語查詢是透過將以空格分隔的詞彙或詞彙前綴序列置於雙引號(")中來指定的。例如
-- Query for all documents that contain the phrase "linux applications". SELECT * FROM docs WHERE docs MATCH '"linux applications"'; -- Query for all documents that contain a phrase that matches "lin* app*". As well as -- "linux applications", this will match common phrases such as "linoleum appliances" -- or "link apprentice". SELECT * FROM docs WHERE docs MATCH '"lin* app*"';
NEAR 查詢。NEAR 查詢是一種查詢,用於傳回包含兩個或多個指定的詞彙或片語且彼此在指定距離範圍內(預設為 10 個或更少的介入詞彙)的文件。NEAR 查詢是透過在兩個片語、令牌或令牌前綴查詢之間加上「NEAR」關鍵字來指定的。若要指定距離範圍而非預設值,可以使用「NEAR/<N>」格式的運算子,其中 <N> 是允許的最大介入詞彙數。例如
-- Virtual table declaration.
CREATE VIRTUAL TABLE docs USING fts4();
-- Virtual table data.
INSERT INTO docs VALUES('SQLite is an ACID compliant embedded relational database management system');
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 10 intervening terms. This matches the only document in
-- table docs (since there are only six terms between "SQLite" and "database"
-- in the document).
SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR database';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 6 intervening terms. This also matches the only document in
-- table docs. Note that the order in which the terms appear in the document
-- does not have to be the same as the order in which they appear in the query.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/6 sqlite';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 5 intervening terms. This query matches no documents.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/5 sqlite';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "database" with not more than 2 terms separating the two. This matches the
-- document stored in table docs.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/2 "ACID compliant"';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "sqlite" with not more than 2 terms separating the two. This also matches
-- the only document stored in table docs.
SELECT * FROM docs WHERE docs MATCH '"ACID compliant" NEAR/2 sqlite';
單一查詢中可以出現多個 NEAR 運算子。在此情況下,由 NEAR 運算子分隔的每對詞彙或片語都必須出現在文件中的指定距離範圍內。使用與上述範例區塊中相同的表格和資料
-- The following query selects documents that contains an instance of the term -- "sqlite" separated by two or fewer terms from an instance of the term "acid", -- which is in turn separated by two or fewer terms from an instance of the term -- "relational". SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR/2 acid NEAR/2 relational'; -- This query matches no documents. There is an instance of the term "sqlite" with -- sufficient proximity to an instance of "acid" but it is not sufficiently close -- to an instance of the term "relational". SELECT * FROM docs WHERE docs MATCH 'acid NEAR/2 sqlite NEAR/2 relational';
片語和 NEAR 查詢不能跨越列中的多個欄位。
上述說明的三種基本查詢類型可以用來查詢符合指定條件的文件的全文索引。使用 FTS 查詢表達式語言,可以在基本查詢的結果上執行各種集合運算。目前支援三種運算
FTS 模組可以編譯為使用兩種略有不同的全文查詢語法版本之一,即「標準」查詢語法和「增強」查詢語法。上述的基本術語、術語前綴、詞組和 NEAR 查詢在兩個語法版本中都是相同的。指定集合運算的方式略有不同。以下兩個小節描述了與集合運算相關的兩個查詢語法的部分。請參閱如何編譯 fts的說明以取得編譯注意事項。
增強查詢語法支援 AND、OR 和 NOT 二元集合運算子。運算子的兩個運算元可以是基本 FTS 查詢,或另一個 AND、OR 或 NOT 集合運算的結果。運算子必須使用大寫字母輸入。否則,它們會被解釋為基本術語查詢,而不是集合運算子。
AND 運算子可以隱式指定。如果兩個基本查詢出現在 FTS 查詢字串中,而沒有運算子將它們分開,則結果與兩個基本查詢由 AND 運算子分隔的結果相同。例如,查詢表達式「隱式運算子」是「隱式 AND 運算子」的更簡潔版本。
-- Virtual table declaration CREATE VIRTUAL TABLE docs USING fts3(); -- Virtual table data INSERT INTO docs(docid, content) VALUES(1, 'a database is a software system'); INSERT INTO docs(docid, content) VALUES(2, 'sqlite is a software system'); INSERT INTO docs(docid, content) VALUES(3, 'sqlite is a database'); -- Return the set of documents that contain the term "sqlite", and the -- term "database". This query will return the document with docid 3 only. SELECT * FROM docs WHERE docs MATCH 'sqlite AND database'; -- Again, return the set of documents that contain both "sqlite" and -- "database". This time, use an implicit AND operator. Again, document -- 3 is the only document matched by this query. SELECT * FROM docs WHERE docs MATCH 'database sqlite'; -- Query for the set of documents that contains either "sqlite" or "database". -- All three documents in the database are matched by this query. SELECT * FROM docs WHERE docs MATCH 'sqlite OR database'; -- Query for all documents that contain the term "database", but do not contain -- the term "sqlite". Document 1 is the only document that matches this criteria. SELECT * FROM docs WHERE docs MATCH 'database NOT sqlite'; -- The following query matches no documents. Because "and" is in lowercase letters, -- it is interpreted as a basic term query instead of an operator. Operators must -- be specified using capital letters. In practice, this query will match any documents -- that contain each of the three terms "database", "and" and "sqlite" at least once. -- No documents in the example data above match this criteria. SELECT * FROM docs WHERE docs MATCH 'database and sqlite';
上述範例都使用基本全文詞彙查詢作為集合運算中兩個運算元。也可以使用片語和 NEAR 查詢,以及其他集合運算的結果。當 FTS 查詢中有多個集合運算時,運算子的優先順序如下
| 運算子 | 加強查詢語法的優先順序 |
|---|---|
| NOT | 最高優先順序(最緊密的分組)。 |
| AND | |
| OR | 最低優先順序(最鬆散的分組)。 |
使用加強查詢語法時,可以使用括號覆寫各種運算子的預設優先順序。例如
-- Return the docid values associated with all documents that contain the
-- two terms "sqlite" and "database", and/or contain the term "library".
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database OR library';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database'
UNION
SELECT docid FROM docs WHERE docs MATCH 'library';
-- Query for the set of documents that contains the term "linux", and at least
-- one of the phrases "sqlite database" and "sqlite library".
SELECT docid FROM docs WHERE docs MATCH '("sqlite database" OR "sqlite library") AND linux';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'linux'
INTERSECT
SELECT docid FROM (
SELECT docid FROM docs WHERE docs MATCH '"sqlite library"'
UNION
SELECT docid FROM docs WHERE docs MATCH '"sqlite database"'
);
使用標準查詢語法的 FTS 查詢集合運算類似於使用加強查詢語法的集合運算,但並不相同。有四個差異,如下所示
僅支援 AND 運算子的隱含版本。將字串「AND」指定為標準查詢語法查詢的一部分會被解釋為包含「and」詞彙的文件集合的詞彙查詢。
不支援括號。
不支援 NOT 運算子。標準查詢語法不支援 NOT 運算子,而是支援一元「-」運算子,可以套用在基本詞彙和詞彙前綴查詢(但不能套用在片語或 NEAR 查詢)。附加一元「-」運算子的詞彙或詞彙前綴不能顯示為 OR 運算子的運算元。FTS 查詢不能完全由附加一元「-」運算子的詞彙或詞彙前綴查詢組成。
-- Search for the set of documents that contain the term "sqlite" but do -- not contain the term "database". SELECT * FROM docs WHERE docs MATCH 'sqlite -database';
集合運算的相對優先順序不同。特別是,使用標準查詢語法時,「OR」運算子的優先順序高於「AND」。使用標準查詢語法時,運算子的優先順序為
| 運算子 | 標準查詢語法優先順序 |
|---|---|
| 單元「-」 | 最高優先順序(最緊密的分組)。 |
| OR | |
| AND | 最低優先順序(最鬆散的分組)。 |
-- Search for documents that contain at least one of the terms "database" -- and "sqlite", and also contain the term "library". Because of the differences -- in operator precedences, this query would have a different interpretation using -- the enhanced query syntax. SELECT * FROM docs WHERE docs MATCH 'sqlite OR database library';
FTS3 和 FTS4 模組提供三個特殊 SQL 標量函數,對於全文查詢系統的開發人員可能很有用:「片段」、「偏移」和「比對資訊」。「片段」和「偏移」函數的目的是讓使用者辨識查詢字詞在傳回文件中的位置。「比對資訊」函數提供使用者指標,可能有助於根據相關性篩選或排序查詢結果。
所有三個特殊 SQL 標量函數的第一個引數必須是函數套用的 FTS 表格的 FTS 隱藏欄位。 FTS 隱藏欄位 是自動產生的欄位,存在於所有 FTS 表格中,其名稱與 FTS 表格本身相同。例如,假設有一個名為「郵件」的 FTS 表格
SELECT offsets(mail) FROM mail WHERE mail MATCH <full-text query expression>; SELECT snippet(mail) FROM mail WHERE mail MATCH <full-text query expression>; SELECT matchinfo(mail) FROM mail WHERE mail MATCH <full-text query expression>;
三個輔助函數僅在使用 FTS 表格全文索引的 SELECT 陳述式中才有用。如果在使用「依 rowid 查詢」或「線性掃描」策略的 SELECT 中使用,則片段和偏移都會傳回一個空字串,而比對資訊函數會傳回大小為零位元組的 blob 值。
所有三個輔助函數從 FTS 查詢表達式中萃取一組「可比對片語」來處理。給定查詢的可比對片語組包含表達式中的所有片語(包括未加引號的標記和標記字首),但排除以單元「-」運算子為字首的片語(標準語法)或作為 NOT 運算子右運算元的子表達式的一部分。
在以下但書的前提下,FTS 表格中與查詢表達式中的可比對片語之一相符的每個標記系列稱為「片語比對」
對於使用全文索引的 SELECT 查詢,offsets() 函數會傳回一個包含一系列以空格分隔的整數的文字值。對於目前列中的每個 短語匹配 中的每個術語,傳回的清單中會有四個整數。每組四個整數的詮釋如下
| 整數 | 詮釋 |
|---|---|
| 0 | 術語實例所在的欄位編號(FTS 表格的最左欄位為 0,往右一個欄位為 1,依此類推)。 |
| 1 | 全文查詢表達式中匹配術語的術語編號。查詢表達式中的術語會依出現順序從 0 開始編號。 |
| 2 | 匹配術語在欄位中的位元組偏移量。 |
| 3 | 匹配術語的位元組大小。 |
下列區塊包含使用 offsets 函數的範例。
CREATE VIRTUAL TABLE mail USING fts3(subject, body);
INSERT INTO mail VALUES('hello world', 'This message is a hello world message.');
INSERT INTO mail VALUES('urgent: serious', 'This mail is seen as a more serious mail');
-- The following query returns a single row (as it matches only the first
-- entry in table "mail". The text returned by the offsets function is
-- "0 0 6 5 1 0 24 5".
--
-- The first set of four integers in the result indicate that column 0
-- contains an instance of term 0 ("world") at byte offset 6. The term instance
-- is 5 bytes in size. The second set of four integers shows that column 1
-- of the matched row contains an instance of term 0 ("world") at byte offset
-- 24. Again, the term instance is 5 bytes in size.
SELECT offsets(mail) FROM mail WHERE mail MATCH 'world';
-- The following query returns also matches only the first row in table "mail".
-- In this case the returned text is "1 0 5 7 1 0 30 7".
SELECT offsets(mail) FROM mail WHERE mail MATCH 'message';
-- The following query matches the second row in table "mail". It returns the
-- text "1 0 28 7 1 1 36 4". Only those occurrences of terms "serious" and "mail"
-- that are part of an instance of the phrase "serious mail" are identified; the
-- other occurrences of "serious" and "mail" are ignored.
SELECT offsets(mail) FROM mail WHERE mail MATCH '"serious mail"';
snippet 函數用於建立格式化的文件文字片段,以作為全文查詢結果報告的一部分顯示。snippet 函數可以傳遞一到六個引數,如下所示
| 引數 | 預設值 | 說明 |
|---|---|---|
| 0 | 不適用 | snippet 函數的第一個引數必須永遠是所查詢的 FTS 表格的 FTS 隱藏欄位,且片段要取自該欄位。 FTS 隱藏欄位 是自動產生的欄位,名稱與 FTS 表格本身相同。 |
| 1 | "<b>" | 「開始比對」文字。 |
| 2 | "</b>" | 「結束比對」文字。 |
| 3 | "<b>...</b>" | 「省略號」文字。 |
| 4 | -1 | FTS 表格欄位編號,用於擷取回傳的文字片段。欄位從左至右編號,從 0 開始。負值表示文字可以從任何欄位擷取。 |
| 5 | -15 | 這個整數參數的絕對值用作回傳文字值中包含的(近似)記號數量。允許的最大絕對值為 64。這個參數的值在以下討論中稱為 N。 |
片段函數首先嘗試在當前列中尋找一個由 |N| 個記號組成的文字片段,其中至少包含一個與當前列中某處比對的每個可比對片語相符的片語比對,其中 |N| 是傳遞給片段函數的第六個參數的絕對值。如果儲存在單一欄位中的文字包含少於 |N| 個記號,則會考慮整個欄位值。文字片段不能跨欄位。
如果可以找到這樣的文字片段,則會回傳它,並套用以下修改
如果可以找到多個此類片段,則優先考慮包含較多「額外」片語比對的片段。所選文字片段的開頭可能會向前或向後移動幾個標記,以嘗試將片語比對集中在片段的中央。
假設 N 是正值,如果找不到包含與每個可比對片語相應的片語比對的片段,則片段函數會嘗試找到兩個大約有 N/2 個標記的片段,它們之間至少包含一個與當前列比對的每個可比對片語相應的片語比對。如果失敗,則會嘗試找到三個各包含 N/3 個標記的片段,最後是四個 N/4 個標記的片段。如果找不到包含所需片語比對的一組四個片段,則會選取提供最佳涵蓋範圍的四個 N/4 個標記的片段。
如果 N 是負值,且找不到包含所需片語比對的單一片段,則片段函數會搜尋兩個各包含 |N| 個標記的片段,然後是三個,然後是四個。換句話說,如果指定的 N 值為負值,則如果需要多個片段才能提供所需的片語比對涵蓋範圍,則不會減少片段的大小。
在找到 M 個片段後,其中 M 如上文所述介於 2 到 4 之間,它們會以排序順序合併在一起,並以「省略號」文字分隔。在傳回文字之前,會對文字執行前面列舉的三項修改。
Note: In this block of examples, newlines and whitespace characters have
been inserted into the document inserted into the FTS table, and the expected
results described in SQL comments. This is done to enhance readability only,
they would not be present in actual SQLite commands or output.
-- Create and populate an FTS table.
CREATE VIRTUAL TABLE text USING fts4();
INSERT INTO text VALUES('
During 30 Nov-1 Dec, 2-3oC drops. Cool in the upper portion, minimum temperature 14-16oC
and cool elsewhere, minimum temperature 17-20oC. Cold to very cold on mountaintops,
minimum temperature 6-12oC. Northeasterly winds 15-30 km/hr. After that, temperature
increases. Northeasterly winds 15-30 km/hr.
');
-- The following query returns the text value:
--
-- "<b>...</b>cool elsewhere, minimum temperature 17-20oC. <b>Cold</b> to very
-- <b>cold</b> on mountaintops, minimum temperature 6<b>...</b>".
--
SELECT snippet(text) FROM text WHERE text MATCH 'cold';
-- The following query returns the text value:
--
-- "...the upper portion, [minimum] [temperature] 14-16oC and cool elsewhere,
-- [minimum] [temperature] 17-20oC. Cold..."
--
SELECT snippet(text, '[', ']', '...') FROM text WHERE text MATCH '"min* tem*"'
matchinfo 函數會傳回一個 blob 值。如果在查詢中使用它,但並未使用全文索引(「依 rowid 查詢」或「線性掃描」),則 blob 的大小為零位元組。否則,blob 會包含零個或多個 32 位元無符號整數(以機器位元組順序)。傳回陣列中整數的確切數量取決於查詢和傳遞給 matchinfo 函數的第二個引數(如果有)的值。
matchinfo 函數會使用一個或兩個引數呼叫。對於所有輔助函數,第一個引數必須是特殊 FTS 隱藏欄位。第二個引數(如果指定)必須是文字值,僅包含字元 'p'、'c'、'n'、'a'、'l'、's'、'x'、'y' 和 'b'。如果未明確提供第二個引數,它會預設為「pcx」。第二個引數在下方稱為「格式字串」。
matchinfo 格式字串中的字元會從左至右處理。格式字串中的每個字元都會導致一個或多個 32 位元無符號整數值新增至傳回陣列。下表中的「值」欄位包含附加至輸出緩衝區的整數值數量,以每個支援的格式字串字元為單位。在給定的公式中,cols 是 FTS 表格中的欄位數量,而 phrases 是查詢中的 可比對字詞 數量。
| 字元 | 值 | 說明 |
|---|---|---|
| p | 1 | 查詢中可比對字詞的數量。 |
| c | 1 | FTS 表格中使用者定義的欄位數量(即不包括 docid 或 FTS 隱藏欄位)。 |
| x | 3 * cols * phrases | 對於字詞和表格欄位的每個不同組合,下列三個值
hits_this_row = array[3 * (c + p*cols) + 0]
hits_all_rows = array[3 * (c + p*cols) + 1]
docs_with_hits = array[3 * (c + p*cols) + 2]
|
| y | cols * phrases | 對於詞組和表格欄的每個不同組合,出現在欄中的可用詞組配對數。這通常與 matchinfo 'x' 旗標 傳回的每組三個值中的第一個值相同。不過,對於任何屬於與目前列不匹配的子運算式的詞組,'y' 旗標報告的比對數為零。這會對包含 AND 運算子且為 OR 運算子子項的運算式造成影響。例如,考慮運算式
a OR (b AND c)和文件 "a c d"matchinfo 'x' 旗標 會針對詞組「a」和「c」報告一個比對。不過,'y' 指令會將「c」的比對數報告為零,因為它是屬於與文件不匹配的子運算式的一部分 - (b AND c)。對於不包含由 OR 運算子衍生的 AND 運算子的查詢,'y' 傳回的結果值永遠與 'x' 傳回的值相同。 整數值陣列中的第一個值對應於表格的最左欄 (第 0 欄) 和查詢中的第一個片語 (第 0 個片語)。對應於其他欄/片語組合的值可以使用下列公式找出 hits_for_phrase_p_column_c = array[c + p*cols]對於使用 OR 運算式或使用 LIMIT 或傳回多列的查詢,'y' matchinfo 選項可能會比 'x' 快。 |
| b | ((cols+31)/32) * phrases | matchinfo 'b' 旗標提供類似於 matchinfo 'y' 旗標 的資訊,但以更精簡的形式提供。'b' 沒有提供精確的比對次數,而是為每個片語/欄組合提供一個布林旗標。如果片語至少出現在該欄一次 (亦即 'y' 對應的整數輸出值為非零),則設定對應的旗標。否則清除。
如果表格有 32 欄或更少欄,則會為查詢中的每個片語輸出一個無符號整數。如果片語至少出現在第 0 欄一次,則設定整數的最低有效位元。如果片語至少出現在第 1 欄一次,則設定第二個最低有效位元。以此類推。 如果表格有超過 32 欄,則會為每個片語的輸出新增一個整數,以表示每個額外的 32 欄或其一部分。對應於同一個片語的整數會群組在一起。例如,如果查詢一個有 45 欄的表格的兩個片語,則會輸出 4 個整數。第一個對應於片語 0 和表格的第 0-31 欄。第二個整數包含片語 0 和第 32-44 欄的資料,以此類推。 例如,如果 nCol 是表格中的欄數,則要判斷片語 p 是否出現在欄 c 中 p_is_in_c = array[p * ((nCol+31)/32)] & (1 << (c % 32)) |
| n | 1 | FTS4 表格中的列數。此值僅在查詢 FTS4 表格時可用,FTS3 時則無法使用。 |
| a | cols | 對於每個欄位,儲存在欄位中的文字值中平均的標記數量(考量 FTS4 表格中的所有列)。此值僅在查詢 FTS4 表格時可用,FTS3 時則無法使用。 |
| l | cols | 對於每個欄位,儲存在 FTS4 表格目前列中的值的長度(以標記為單位)。此值僅在查詢 FTS4 表格時可用,FTS3 時則無法使用。而且僅當「matchinfo=fts3」指令未指定為建立 FTS4 表格時所使用的「CREATE VIRTUAL TABLE」陳述式的一部分時才可用。 |
| s | cols | 對於每個欄位,欄位值與查詢文字共有的詞組比對最長子序列的長度。例如,如果表格欄位包含文字「a b c d e」,而查詢為「a c \"d e\"」,則最長共有子序列的長度為 2(詞組「c」後接詞組「d e」)。 |
例如
-- Create and populate an FTS4 table with two columns:
CREATE VIRTUAL TABLE t1 USING fts4(a, b);
INSERT INTO t1 VALUES('transaction default models default', 'Non transaction reads');
INSERT INTO t1 VALUES('the default transaction', 'these semantics present');
INSERT INTO t1 VALUES('single request', 'default data');
-- In the following query, no format string is specified and so it defaults
-- to "pcx". It therefore returns a single row consisting of a single blob
-- value 80 bytes in size (20 32-bit integers - 1 for "p", 1 for "c" and
-- 3*2*3 for "x"). If each block of 4 bytes in the blob is interpreted
-- as an unsigned integer in machine byte-order, the values will be:
--
-- 3 2 1 3 2 0 1 1 1 2 2 0 1 1 0 0 0 1 1 1
--
-- The row returned corresponds to the second entry inserted into table t1.
-- The first two integers in the blob show that the query contained three
-- phrases and the table being queried has two columns. The next block of
-- three integers describes column 0 (in this case column "a") and phrase
-- 0 (in this case "default"). The current row contains 1 hit for "default"
-- in column 0, of a total of 3 hits for "default" that occur in column
-- 0 of any table row. The 3 hits are spread across 2 different rows.
--
-- The next set of three integers (0 1 1) pertain to the hits for "default"
-- in column 1 of the table (0 in this row, 1 in all rows, spread across
-- 1 rows).
--
SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'default transaction "these semantics"';
-- The format string for this query is "ns". The output array will therefore
-- contain 3 integer values - 1 for "n" and 2 for "s". The query returns
-- two rows (the first two rows in the table match). The values returned are:
--
-- 3 1 1
-- 3 2 0
--
-- The first value in the matchinfo array returned for both rows is 3 (the
-- number of rows in the table). The following two values are the lengths
-- of the longest common subsequence of phrase matches in each column.
SELECT matchinfo(t1, 'ns') FROM t1 WHERE t1 MATCH 'default transaction';
matchinfo 函數比 snippet 或 offsets 函數快很多。這是因為 snippet 和 offsets 的實作需要從磁碟中擷取正在分析的文件,而 matchinfo 所需的所有資料都可作為全文索引的一部分提供,而全文索引是實作全文查詢本身所必需的。這表示在以下兩個查詢中,第一個查詢的執行速度可能比第二個查詢快一個數量級
SELECT docid, matchinfo(tbl) FROM tbl WHERE tbl MATCH <query expression>; SELECT docid, offsets(tbl) FROM tbl WHERE tbl MATCH <query expression>;
matchinfo 函數提供所有計算機率性「詞袋」相關性評分所需資訊,例如 Okapi BM25/BM25F,可將其用於在全文搜尋應用程式中排序結果。本文件附錄 A「搜尋應用程式提示」包含有效使用 matchinfo() 函數的範例。
自 3.7.6 版 (2011-04-12) 起,SQLite 包含一個名為「fts4aux」的新虛擬表格模組,可直接用來檢查現有 FTS 表格的全文索引。儘管名稱如此,fts4aux 用於 FTS3 表格時與用於 FTS4 表格時一樣有效。Fts4aux 表格為唯讀。修改 fts4aux 表格內容的唯一方法是修改關聯 FTS 表格的內容。fts4aux 模組自動包含在所有 包含 FTS 的建置 中。
fts4aux 虛擬表格以一個或兩個引數建構。當使用一個引數時,該引數是它將用於存取的 FTS 表格的非限定名稱。若要存取不同資料庫中的表格(例如,建立一個 TEMP fts4aux 表格,它將存取 MAIN 資料庫中的 FTS3 表格),請使用兩個引數形式,並在第一個引數中提供目標資料庫的名稱(例如:「main」),在第二個引數中提供 FTS3/4 表格的名稱。(fts4aux 的兩個引數形式已新增至 SQLite 3.7.17 版 (2013-05-20),且會在先前版本中擲回錯誤。)例如
-- Create an FTS4 table CREATE VIRTUAL TABLE ft USING fts4(x, y); -- Create an fts4aux table to access the full-text index for table "ft" CREATE VIRTUAL TABLE ft_terms USING fts4aux(ft); -- Create a TEMP fts4aux table accessing the "ft" table in "main" CREATE VIRTUAL TABLE temp.ft_terms_2 USING fts4aux(main,ft);
對於 FTS 表格中出現的每個詞彙,fts4aux 表格中有 2 到 N+1 列,其中 N 是關聯 FTS 表格中的使用者定義欄位數。fts4aux 表格始終有相同的四個欄位,如下,由左至右
| 欄位名稱 | 欄位內容 |
|---|---|
| term | 包含此列的詞彙文字。 |
| col | 此欄位可能包含文字值 '*'(即單一字元,U+002a)或介於 0 到 N-1 之間的整數,其中 N 又是對應 FTS 表格中使用者定義欄位的數量。 |
| documents |
此欄位總是包含大於 0 的整數值。
如果「col」欄位包含值 '*',則此欄位包含 FTS 表格中包含至少一個詞彙實例(在任何欄位中)的列數。如果 col 包含整數值,則此欄位包含 FTS 表格中包含至少一個詞彙實例的列數,該詞彙實例出現在由 col 值識別的欄位中。與往常一樣,FTS 表格的欄位從左到右編號,從 0 開始。 |
| occurrences |
此欄位也總是包含大於 0 的整數值。
如果「col」欄位包含值 '*',則此欄位包含 FTS 表格中所有列中詞彙的總實例數(在任何欄位中)。否則,如果 col 包含整數值,則此欄位包含出現在由 col 值識別的 FTS 表格欄位中的詞彙總實例數。 |
| languageid (隱藏) |
此欄位決定從 FTS3/4 表格中擷取詞彙時使用哪一個 languageid。
languageid 的預設值為 0。如果在 WHERE 子句約束中指定了其他語言,則會使用該其他語言取代 0。每個查詢只能有一個 languageid。換句話說,WHERE 子句不能包含語言識別碼的範圍約束或 IN 算子。 |
例如,使用上面建立的表格
INSERT INTO ft(x, y) VALUES('Apple banana', 'Cherry');
INSERT INTO ft(x, y) VALUES('Banana Date Date', 'cherry');
INSERT INTO ft(x, y) VALUES('Cherry Elderberry', 'Elderberry');
-- The following query returns this data:
--
-- apple | * | 1 | 1
-- apple | 0 | 1 | 1
-- banana | * | 2 | 2
-- banana | 0 | 2 | 2
-- cherry | * | 3 | 3
-- cherry | 0 | 1 | 1
-- cherry | 1 | 2 | 2
-- date | * | 1 | 2
-- date | 0 | 1 | 2
-- elderberry | * | 1 | 2
-- elderberry | 0 | 1 | 1
-- elderberry | 1 | 1 | 1
--
SELECT term, col, documents, occurrences FROM ft_terms;
在範例中,「term」欄位的數值都是小寫,即使它們是以混合大小寫的方式插入到「ft」表格中。這是因為 fts4aux 表格包含由 分詞器 從文件文字中萃取的詞彙。在這個案例中,由於「ft」表格使用 簡單分詞器,這表示所有詞彙都已轉換成小寫。此外,沒有(例如)「term」欄位設定為「apple」,且「col」欄位設定為 1 的列。由於第 1 欄中沒有「apple」詞彙的實例,因此 fts4aux 表格中沒有這個列。
在交易期間,寫入 FTS 表格的一些資料可能會快取在記憶體中,而且只有在交易提交時才會寫入資料庫。然而,fts4aux 模組的實作只能從資料庫讀取資料。實際上,這表示如果從已修改關聯 FTS 表格的交易中查詢 fts4aux 表格,查詢結果可能只反映所做變更的(可能是空的)子集。
如果「CREATE VIRTUAL TABLE」陳述式指定模組 FTS4(不是 FTS3),則特殊指令(FTS4 選項)類似於「tokenize=*」選項,也可能出現在欄位名稱的地方。FTS4 選項包含選項名稱,後面接著一個「=」字元,然後是選項值。選項值可以選擇用單引號或雙引號括起來,嵌入的引號字元以與 SQL 文字相同的逃逸方式逃逸。在「=」字元的兩側不能有空白。例如,要建立一個 FTS4 表格,選項「matchinfo」的值設定為「fts3」
-- Create a reduced-footprint FTS4 table. CREATE VIRTUAL TABLE papers USING fts4(author, document, matchinfo=fts3);
FTS4 目前支援下列選項
| 選項 | 詮釋 |
|---|---|
| compress | compress 選項用於指定壓縮函數。如果未同時指定解壓縮函數,則指定壓縮函數會產生錯誤。請參閱下方以取得詳細資訊。 |
| content | content 允許將要建立索引的文字儲存在與 FTS4 表格不同的個別表格中,甚至儲存在 SQLite 外部。 |
| languageid | languageid 選項會讓 FTS4 表格具備額外的隱藏整數欄位,用於辨識每一列中文字的語言。使用 languageid 選項可讓同一個 FTS4 表格容納多種語言或腳本的文字,每一種語言或腳本都有不同的分詞規則,而且可以獨立查詢每一種語言。 |
| matchinfo | 當設定為「fts3」值時,matchinfo 選項會減少 FTS4 儲存的資訊量,因此 matchinfo() 的「l」選項將不再可用。 |
| notindexed | 此選項用於指定未建立索引的欄位名稱。儲存在未建立索引的欄位中的值不會與 MATCH 查詢相符。輔助函數也不會辨識這些值。單一 CREATE VIRTUAL TABLE 陳述式可以包含任意數量的 notindexed 選項。 |
| order | 「order」選項可以設定為「DESC」或「ASC」(大小寫皆可)。如果設定為「DESC」,FTS4 會以最佳化方式儲存資料,以便依 docid 降序傳回結果。如果設定為「ASC」(預設值),資料結構會最佳化,以便依 docid 升序傳回結果。換句話說,如果在 FTS4 表格上執行的許多查詢都使用「ORDER BY docid DESC」,則在 CREATE VIRTUAL TABLE 陳述式中加入「order=desc」選項可能會改善效能。 |
| prefix | 此選項可以設定為正整數的逗號分隔清單。對於清單中的每個整數 N,資料庫檔案中會建立一個獨立索引,以最佳化查詢字詞長度為 N 位元組(不含 '*' 字元)且使用 UTF-8 編碼的前置字串查詢。請參閱下方以取得詳細資訊。 |
| uncompress | 此選項用於指定 uncompress 函式。如果未同時指定 compress 函式,則指定 uncompress 函式會產生錯誤。請參閱下方以取得詳細資訊。 |
在使用 FTS4 時,指定包含「=」字元且不是「tokenize=*」規格或已識別的 FTS4 選項的欄位名稱會產生錯誤。在 FTS3 中,未識別的指令中的第一個記號會被解釋為欄位名稱。類似地,在使用 FTS4 時,在單一表格宣告中指定多個「tokenize=*」指令會產生錯誤,而 FTS3 會將第二個和後續的「tokenize=*」指令解釋為欄位名稱。例如
-- An error. FTS4 does not recognize the directive "xyz=abc". CREATE VIRTUAL TABLE papers USING fts4(author, document, xyz=abc); -- Create an FTS3 table with three columns - "author", "document" -- and "xyz". CREATE VIRTUAL TABLE papers USING fts3(author, document, xyz=abc); -- An error. FTS4 does not allow multiple tokenize=* directives CREATE VIRTUAL TABLE papers USING fts4(tokenize=porter, tokenize=simple); -- Create an FTS3 table with a single column named "tokenize". The -- table uses the "porter" tokenizer. CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple); -- An error. Cannot create a table with two columns named "tokenize". CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple, tokenize=icu);
compress 和 uncompress 選項允許 FTS4 內容以壓縮形式儲存在資料庫中。兩個選項都應設定為使用sqlite3_create_function()註冊的 SQL 標量函式的名稱,該函式接受單一引數。
compress 函式應傳回傳遞給它的值的壓縮版本。每次資料寫入 FTS4 表格時,每個欄位值都會傳遞給 compress 函式,而結果值會儲存在資料庫中。compress 函式可以傳回任何類型的 SQLite 值(blob、text、real、integer 或 null)。
解壓縮函數應解壓縮先前由壓縮函數壓縮的資料。換句話說,對於所有 SQLite 值 X,uncompress(compress(X)) 應等於 X。當 FTS4 從資料庫讀取已由壓縮函數壓縮的資料時,會在使用前將其傳遞給解壓縮函數。
如果指定的壓縮或解壓縮函數不存在,仍可建立表格。只有在讀取 FTS4 表格(如果解壓縮函數不存在)或寫入(如果不存在的函數是壓縮函數)時才會傳回錯誤。
-- Create an FTS4 table that stores data in compressed form. This -- assumes that the scalar functions zip() and unzip() have been (or -- will be) added to the database handle. CREATE VIRTUAL TABLE papers USING fts4(author, document, compress=zip, uncompress=unzip);
在實作壓縮和解壓縮函數時,請務必注意資料類型。特別是,當使用者從壓縮的 FTS 表格讀取值時,FTS 傳回的值與解壓縮函數傳回的值完全相同,包括資料類型。如果該資料類型與傳遞給壓縮函數的原始值資料類型不同(例如,如果解壓縮函數傳回 BLOB,而壓縮最初傳遞的是 TEXT),則使用者的查詢可能無法按預期運作。
content 選項允許 FTS4 放棄儲存正在編製索引的文字。content 選項可用於兩種方式
編製索引的文件根本不會儲存在 SQLite 資料庫中(「無內容」FTS4 表格),或
編製索引的文件儲存在由使用者建立和管理的資料庫表格中(「外部內容」FTS4 表格)。
由於編製索引的文件本身通常遠大於全文索引,因此可以使用 content 選項來節省大量空間。
為了建立完全不儲存編製索引的文件副本的 FTS4 表格,content 選項應設定為空字串。例如,以下 SQL 會建立一個具有三個欄位(「a」、「b」和「c」)的 FTS4 表格
CREATE VIRTUAL TABLE t1 USING fts4(content="", a, b, c);
資料可以使用 INSERT 陳述句插入到此類 FTS4 表格中。但是,與一般的 FTS4 表格不同,使用者必須提供明確的整數 docid 值。例如
-- This statement is Ok:
INSERT INTO t1(docid, a, b, c) VALUES(1, 'a b c', 'd e f', 'g h i');
-- This statement causes an error, as no docid value has been provided:
INSERT INTO t1(a, b, c) VALUES('j k l', 'm n o', 'p q r');
無法 UPDATE 或 DELETE 儲存在無內容 FTS4 表格中的列。嘗試這麼做會產生錯誤。
無內容 FTS4 表格也支援 SELECT 陳述句。但是,嘗試擷取 docid 欄位以外的任何表格欄位值會產生錯誤。可以使用輔助函式 matchinfo(),但不能使用 snippet() 和 offsets()。例如
-- The following statements are Ok: SELECT docid FROM t1 WHERE t1 MATCH 'xxx'; SELECT docid FROM t1 WHERE a MATCH 'xxx'; SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'xxx'; -- The following statements all cause errors, as the value of columns -- other than docid are required to evaluate them. SELECT * FROM t1; SELECT a, b FROM t1 WHERE t1 MATCH 'xxx'; SELECT docid FROM t1 WHERE a LIKE 'xxx%'; SELECT snippet(t1) FROM t1 WHERE t1 MATCH 'xxx';
嘗試擷取 docid 以外的欄位值所產生的錯誤是在 sqlite3_step() 中發生的執行時期錯誤。在某些情況下,例如如果 SELECT 查詢中的 MATCH 表達式比對到零列,即使陳述句確實參照 docid 以外的欄位值,也可能完全沒有錯誤。
「外部內容」FTS4 表格類似於無內容表格,但如果查詢的評估需要 docid 以外的欄位值,FTS4 會嘗試從使用者指定的表格(或檢視,或虛擬表格)(以下稱為「內容表格」)擷取該值。FTS4 模組絕不會寫入內容表格,而寫入內容表格也不會影響全文索引。使用者有責任確保內容表格和全文索引是一致的。
透過將 content 選項設定為 FTS4 可以查詢的表格(或檢視,或虛擬表格)名稱,來建立外部內容 FTS4 表格,以在需要時擷取欄位值。如果指定的表格不存在,則外部內容表格的行為方式與無內容表格相同。例如
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c); CREATE VIRTUAL TABLE t3 USING fts4(content="t2", a, c);
假設指定的表格確實存在,則其欄位必須與 FTS 表格所定義的欄位相同或為其超集。外部表格也必須與 FTS 表格位於同一個資料庫檔案中。換句話說,外部表格不能位於使用 ATTACH 連接的不同資料庫檔案中,也不能讓 FTS 表格和外部內容之一位於 TEMP 資料庫中,而另一個位於 MAIN 等持續性資料庫檔案中。
當使用者對 FTS 表格的查詢需要 docid 以外的欄位值時,FTS 會嘗試從內容表格中具有與目前 FTS docid 相等的 rowid 值之列的對應欄位讀取請求的值。只能查詢在 FTS/34 表格宣告中重複的內容表格欄位子集,若要擷取任何其他欄位的值,必須直接查詢內容表格。或者,如果在內容表格中找不到此類列,則改為使用 NULL 值。例如
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c); CREATE VIRTUAL TABLE t3 USING fts4(content="t2", b, c); INSERT INTO t2 VALUES(2, 'a b', 'c d', 'e f'); INSERT INTO t2 VALUES(3, 'g h', 'i j', 'k l'); INSERT INTO t3(docid, b, c) SELECT id, b, c FROM t2; -- The following query returns a single row with two columns containing -- the text values "i j" and "k l". -- -- The query uses the full-text index to discover that the MATCH -- term matches the row with docid=3. It then retrieves the values -- of columns b and c from the row with rowid=3 in the content table -- to return. -- SELECT * FROM t3 WHERE t3 MATCH 'k'; -- Following the UPDATE, the query still returns a single row, this -- time containing the text values "xxx" and "yyy". This is because the -- full-text index still indicates that the row with docid=3 matches -- the FTS4 query 'k', even though the documents stored in the content -- table have been modified. -- UPDATE t2 SET b = 'xxx', c = 'yyy' WHERE rowid = 3; SELECT * FROM t3 WHERE t3 MATCH 'k'; -- Following the DELETE below, the query returns one row containing two -- NULL values. NULL values are returned because FTS is unable to find -- a row with rowid=3 within the content table. -- DELETE FROM t2; SELECT * FROM t3 WHERE t3 MATCH 'k';
當從外部內容 FTS4 表格刪除列時,FTS4 需要從內容表格中擷取要刪除的列值。這是為了讓 FTS4 能夠更新已刪除列中出現的每個標記的全文索引項目,以指出該列已刪除。如果找不到內容表格列,或如果它包含與 FTS 索引內容不一致的值,結果可能難以預測。FTS 索引可能包含與已刪除列對應的項目,這可能導致後續 SELECT 查詢傳回看似無意義的結果。當更新列時也適用相同情況,因為在內部,UPDATE 與 DELETE 接著 INSERT 相同。
這表示為了讓 FTS 與外部內容表格保持同步,任何 UPDATE 或 DELETE 作業都必須先套用至 FTS 表格,然後再套用至外部內容表格。例如
CREATE TABLE t1_real(id INTEGER PRIMARY KEY, a, b, c, d); CREATE VIRTUAL TABLE t1_fts USING fts4(content="t1_real", b, c); -- This works. When the row is removed from the FTS table, FTS retrieves -- the row with rowid=123 and tokenizes it in order to determine the entries -- that must be removed from the full-text index. -- DELETE FROM t1_fts WHERE rowid = 123; DELETE FROM t1_real WHERE rowid = 123; -- This does not work. By the time the FTS table is updated, the row -- has already been deleted from the underlying content table. As a result -- FTS is unable to determine the entries to remove from the FTS index and -- so the index and content table are left out of sync. -- DELETE FROM t1_real WHERE rowid = 123; DELETE FROM t1_fts WHERE rowid = 123;
有些使用者可能希望使用資料庫觸發器讓全文索引與儲存在內容表格中的文件集保持最新,而不是分別寫入全文索引和內容表格。例如,使用先前範例中的表格
CREATE TRIGGER t2_bu BEFORE UPDATE ON t2 BEGIN DELETE FROM t3 WHERE docid=old.rowid; END; CREATE TRIGGER t2_bd BEFORE DELETE ON t2 BEGIN DELETE FROM t3 WHERE docid=old.rowid; END; CREATE TRIGGER t2_au AFTER UPDATE ON t2 BEGIN INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c); END; CREATE TRIGGER t2_ai AFTER INSERT ON t2 BEGIN INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c); END;
DELETE 觸發器必須在內容表上執行實際刪除之前觸發。這樣,FTS4 才能仍然擷取原始值,以更新全文索引。而 INSERT 觸發器必須在插入新列之後觸發,以便處理系統內自動指派 rowid 的情況。UPDATE 觸發器必須分成兩部分,一個在內容表更新之前觸發,另一個在更新之後觸發,原因相同。
FTS4「重建」指令會刪除整個全文索引,並根據內容表中的目前文件集重建索引。假設「t3」又是外部內容 FTS4 表的名稱,則重建指令如下所示
INSERT INTO t3(t3) VALUES('rebuild');
此指令也可以用於一般 FTS4 表,例如,如果分詞器的實作有變更。嘗試重建由無內容 FTS4 表維護的全文索引時會發生錯誤,因為沒有內容可供重建。
當存在 languageid 選項時,它會指定另一個隱藏欄位的名稱,該欄位會新增到 FTS4 表中,並用於指定儲存在 FTS4 表中每一列的語言。languageid 隱藏欄位的名稱必須與 FTS4 表中的所有其他欄位名稱不同。範例
CREATE VIRTUAL TABLE t1 USING fts4(x, y, languageid="lid")
languageid 欄位的預設值為 0。插入到 languageid 欄位的任何值都會轉換為 32 位元(而非 64 位元)有號整數。
預設情況下,FTS 查詢(使用 MATCH 運算子)只會考慮 languageid 欄位設定為 0 的列。若要查詢其他 languageid 值的列,請使用下列形式的約束條件:
SELECT * FROM t1 WHERE t1 MATCH 'abc' AND lid=5;
It is not possible for a single FTS query to return rows with different languageid values. The results of adding WHERE clauses that use other operators (e.g. lid!=5, or lid<=5) are undefined.
If the content option is used along with the languageid option, then the named languageid column must exist in the content= table (subject to the usual rules - if a query never needs to read the content table then this restriction does not apply).
When the languageid option is used, SQLite invokes the xLanguageid() on the sqlite3_tokenizer_module object immediately after the object is created in order to pass in the language id that the tokenizer should use. The xLanguageid() method will never be called more than once for any single tokenizer object. The fact that different languages might be tokenized differently is one reason why no single FTS query can return rows with different languageid values.
The matchinfo option may only be set to the value "fts3". Attempting to set matchinfo to anything other than "fts3" is an error. If this option is specified, then some of the extra information stored by FTS4 is omitted. This reduces the amount of disk space consumed by an FTS4 table until it is almost the same as the amount that would be used by the equivalent FTS3 table, but also means that the data accessed by passing the 'l' flag to the matchinfo() function is not available.
Normally, the FTS module maintains an inverted index of all terms in all columns of the table. This option is used to specify the name of a column for which entries should not be added to the index. Multiple "notindexed" options may be used to specify that multiple columns should be omitted from the index. For example:
-- Create an FTS4 table for which only the contents of columns c2 and c4 -- are tokenized and added to the inverted index. CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, c3, c4, notindexed=c1, notindexed=c3);
Values stored in unindexed columns are not eligible to match MATCH operators. They do not influence the results of the offsets() or matchinfo() auxiliary functions. Nor will the snippet() function ever return a snippet based on a value stored in an unindexed column.
The FTS4 prefix option causes FTS to index term prefixes of specified lengths in the same way that it always indexes complete terms. The prefix option must be set to a comma separated list of positive non-zero integers. For each value N in the list, prefixes of length N bytes (when encoded using UTF-8) are indexed. FTS4 uses term prefix indexes to speed up prefix queries. The cost, of course, is that indexing term prefixes as well as complete terms increases the database size and slows down write operations on the FTS4 table.
Prefix indexes may be used to optimize prefix queries in two cases. If the query is for a prefix of N bytes, then a prefix index created with "prefix=N" provides the best optimization. Or, if no "prefix=N" index is available, a "prefix=N+1" index may be used instead. Using a "prefix=N+1" index is less efficient than a "prefix=N" index, but is better than no prefix index at all.
-- Create an FTS4 table with indexes to optimize 2 and 4 byte prefix queries. CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, prefix="2,4"); -- The following two queries are both optimized using the prefix indexes. SELECT * FROM t1 WHERE t1 MATCH 'ab*'; SELECT * FROM t1 WHERE t1 MATCH 'abcd*'; -- The following two queries are both partially optimized using the prefix -- indexes. The optimization is not as pronounced as it is for the queries -- above, but still an improvement over no prefix indexes at all. SELECT * FROM t1 WHERE t1 MATCH 'a*'; SELECT * FROM t1 WHERE t1 MATCH 'abc*';
Special INSERT operates can be used to issue commands to FTS3 and FTS4 tables. Every FTS3 and FTS4 has a hidden, read-only column which is the same name as the table itself. INSERTs into this hidden column are interpreted as commands to the FTS3/4 table. For a table with the name "xyz" the following commands are supported:
INSERT INTO xyz(xyz) VALUES('optimize');
INSERT INTO xyz(xyz) VALUES('rebuild');
INSERT INTO xyz(xyz) VALUES('integrity-check');
INSERT INTO xyz(xyz) VALUES('merge=X,Y');
INSERT INTO xyz(xyz) VALUES('automerge=N');
The "optimize" command causes FTS3/4 to merge together all of its inverted index b-trees into one large and complete b-tree. Doing an optimize will make subsequent queries run faster since there are fewer b-trees to search, and it may reduce disk usage by coalescing redundant entries. However, for a large FTS table, running optimize can be as expensive as running VACUUM. The optimize command essentially has to read and write the entire FTS table, resulting in a large transaction.
In batch-mode operation, where an FTS table is initially built up using a large number of INSERT operations, then queried repeatedly without further changes, it is often a good idea to run "optimize" after the last INSERT and before the first query.
The "rebuild" command causes SQLite to discard the entire FTS3/4 table and then rebuild it again from original text. The concept is similar to REINDEX, only that it applies to an FTS3/4 table instead of an ordinary index.
The "rebuild" command should be run whenever the implementation of a custom tokenizer changes, so that all content can be retokenized. The "rebuild" command is also useful when using the FTS4 content option after changes have been made to the original content table.
The "integrity-check" command causes SQLite to read and verify the accuracy of all inverted indices in an FTS3/4 table by comparing those inverted indices against the original content. The "integrity-check" command silently succeeds if the inverted indices are all ok, but will fail with an SQLITE_CORRUPT error if any problems are found.
The "integrity-check" command is similar in concept to PRAGMA integrity_check. In a working system, the "integrity-command" should always be successful. Possible causes of integrity-check failures include:
The "merge=X,Y" command (where X and Y are integers) causes SQLite to do a limited amount of work toward merging the various inverted index b-trees of an FTS3/4 table together into one large b-tree. The X value is the target number of "blocks" to be merged, and Y is the minimum number of b-tree segments on a level required before merging will be applied to that level. The value of Y should be between 2 and 16 with a recommended value of 8. The value of X can be any positive integer but values on the order of 100 to 300 are recommended.
When an FTS table accumulates 16 b-tree segments at the same level, the next INSERT into that table will cause all 16 segments to be merged into a single b-tree segment at the next higher level. The effect of these level merges is that most INSERTs into an FTS table are very fast and take minimal memory, but an occasional INSERT is slow and generates a large transaction because of the need to do merging. This results in "spiky" performance of INSERTs.
To avoid spiky INSERT performance, an application can run the "merge=X,Y" command periodically, possibly in an idle thread or idle process, to ensure that the FTS table never accumulates too many b-tree segments at the same level. INSERT performance spikes can generally be avoided, and performance of FTS3/4 can be maximized, by running "merge=X,Y" after every few thousand document inserts. Each "merge=X,Y" command will run in a separate transaction (unless they are grouped together using BEGIN...COMMIT, of course). The transactions can be kept small by choosing a value for X in the range of 100 to 300. The idle thread that is running the merge commands can know when it is done by checking the difference in sqlite3_total_changes() before and after each "merge=X,Y" command and stopping the loop when the difference drops below two.
The "automerge=N" command (where N is an integer between 0 and 15, inclusive) is used to configure an FTS3/4 tables "automerge" parameter, which controls automatic incremental inverted index merging. The default automerge value for new tables is 0, meaning that automatic incremental merging is completely disabled. If the value of the automerge parameter is modified using the "automerge=N" command, the new parameter value is stored persistently in the database and is used by all subsequently established database connections.
Setting the automerge parameter to a non-zero value enables automatic incremental merging. This causes SQLite to do a small amount of inverted index merging after every INSERT operation. The amount of merging performed is designed so that the FTS3/4 table never reaches a point where it has 16 segments at the same level and hence has to do a large merge in order to complete an insert. In other words, automatic incremental merging is designed to prevent spiky INSERT performance.
The downside of automatic incremental merging is that it makes every INSERT, UPDATE, and DELETE operation on an FTS3/4 table run a little slower, since extra time must be used to do the incremental merge. For maximum performance, it is recommended that applications disable automatic incremental merge and instead use the "merge" command in an idle process to keep the inverted indices well merged. But if the structure of an application does not easily allow for idle processes, the use of automatic incremental merge is a very reasonable fallback solution.
The actual value of the automerge parameter determines the number of index segments merged simultaneously by an automatic inverted index merge. If the value is set to N, the system waits until there are at least N segments on a single level before beginning to incrementally merge them. Setting a lower value of N causes segments to be merged more quickly, which may speed up full-text queries and, if the workload contains UPDATE or DELETE operations as well as INSERTs, reduce the space on disk consumed by the full-text index. However, it also increases the amount of data written to disk.
For general use in cases where the workload contains few UPDATE or DELETE operations, a good choice for automerge is 8. If the workload contains many UPDATE or DELETE commands, or if query speed is a concern, it may be advantageous to reduce automerge to 2.
For reasons of backwards compatibility, the "automerge=1" command sets the automerge parameter to 8, not 1 (a value of 1 would make no sense anyway, as merging data from a single segment is a no-op).
An FTS tokenizer is a set of rules for extracting terms from a document or basic FTS full-text query.
Unless a specific tokenizer is specified as part of the CREATE VIRTUAL TABLE statement used to create the FTS table, the default tokenizer, "simple", is used. The simple tokenizer extracts tokens from a document or basic FTS full-text query according to the following rules:
A term is a contiguous sequence of eligible characters, where eligible characters are all alphanumeric characters and all characters with Unicode codepoint values greater than or equal to 128. All other characters are discarded when splitting a document into terms. Their only contribution is to separate adjacent terms.
All uppercase characters within the ASCII range (Unicode codepoints less than 128), are transformed to their lowercase equivalents as part of the tokenization process. Thus, full-text queries are case-insensitive when using the simple tokenizer.
For example, when a document containing the text "Right now, they're very frustrated.", the terms extracted from the document and added to the full-text index are, in order, "right now they re very frustrated". Such a document would match a full-text query such as "MATCH 'Frustrated'", as the simple tokenizer transforms the term in the query to lowercase before searching the full-text index.
As well as the "simple" tokenizer, the FTS source code features a tokenizer that uses the Porter Stemming algorithm. This tokenizer uses the same rules to separate the input document into terms including folding all terms into lower case, but also uses the Porter Stemming algorithm to reduce related English language words to a common root. For example, using the same input document as in the paragraph above, the porter tokenizer extracts the following tokens: "right now thei veri frustrat". Even though some of these terms are not even English words, in some cases using them to build the full-text index is more useful than the more intelligible output produced by the simple tokenizer. Using the porter tokenizer, the document not only matches full-text queries such as "MATCH 'Frustrated'", but also queries such as "MATCH 'Frustration'", as the term "Frustration" is reduced by the Porter stemmer algorithm to "frustrat" - just as "Frustrated" is. So, when using the porter tokenizer, FTS is able to find not just exact matches for queried terms, but matches against similar English language terms. For more information on the Porter Stemmer algorithm, please refer to the page linked above.
Example illustrating the difference between the "simple" and "porter" tokenizers:
-- Create a table using the simple tokenizer. Insert a document into it.
CREATE VIRTUAL TABLE simple USING fts3(tokenize=simple);
INSERT INTO simple VALUES('Right now they''re very frustrated');
-- The first of the following two queries matches the document stored in
-- table "simple". The second does not.
SELECT * FROM simple WHERE simple MATCH 'Frustrated';
SELECT * FROM simple WHERE simple MATCH 'Frustration';
-- Create a table using the porter tokenizer. Insert the same document into it
CREATE VIRTUAL TABLE porter USING fts3(tokenize=porter);
INSERT INTO porter VALUES('Right now they''re very frustrated');
-- Both of the following queries match the document stored in table "porter".
SELECT * FROM porter WHERE porter MATCH 'Frustrated';
SELECT * FROM porter WHERE porter MATCH 'Frustration';
If this extension is compiled with the SQLITE_ENABLE_ICU pre-processor symbol defined, then there exists a built-in tokenizer named "icu" implemented using the ICU library. The first argument passed to the xCreate() method (see fts3_tokenizer.h) of this tokenizer may be an ICU locale identifier. For example "tr_TR" for Turkish as used in Turkey, or "en_AU" for English as used in Australia. For example:
CREATE VIRTUAL TABLE thai_text USING fts3(text, tokenize=icu th_TH)
The ICU tokenizer implementation is very simple. It splits the input text according to the ICU rules for finding word boundaries and discards any tokens that consist entirely of white-space. This may be suitable for some applications in some locales, but not all. If more complex processing is required, for example to implement stemming or discard punctuation, this can be done by creating a tokenizer implementation that uses the ICU tokenizer as part of its implementation.
The "unicode61" tokenizer is available beginning with SQLite version 3.7.13 (2012-06-11). Unicode61 works very much like "simple" except that it does simple unicode case folding according to rules in Unicode Version 6.1 and it recognizes unicode space and punctuation characters and uses those to separate tokens. The simple tokenizer only does case folding of ASCII characters and only recognizes ASCII space and punctuation characters as token separators.
By default, "unicode61" attempts to remove diacritics from Latin script characters. This behaviour can be overridden by adding the tokenizer argument "remove_diacritics=0". For example:
-- Create tables that remove alldiacritics from Latin script characters -- as part of tokenization. CREATE VIRTUAL TABLE txt1 USING fts4(tokenize=unicode61); CREATE VIRTUAL TABLE txt2 USING fts4(tokenize=unicode61 "remove_diacritics=2"); -- Create a table that does not remove diacritics from Latin script -- characters as part of tokenization. CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "remove_diacritics=0");
The remove_diacritics option may be set to "0", "1" or "2". The default value is "1". If it is set to "1" or "2", then diacritics are removed from Latin script characters as described above. However, if it is set to "1", then diacritics are not removed in the fairly uncommon case where a single unicode codepoint is used to represent a character with more that one diacritic. For example, diacritics are not removed from codepoint 0x1ED9 ("LATIN SMALL LETTER O WITH CIRCUMFLEX AND DOT BELOW"). This is technically a bug, but cannot be fixed without creating backwards compatibility problems. If this option is set to "2", then diacritics are correctly removed from all Latin characters.
It is also possible to customize the set of codepoints that unicode61 treats as separator characters. The "separators=" option may be used to specify one or more extra characters that should be treated as separator characters, and the "tokenchars=" option may be used to specify one or more extra characters that should be treated as part of tokens instead of as separator characters. For example:
-- Create a table that uses the unicode61 tokenizer, but considers "." -- and "=" characters to be part of tokens, and capital "X" characters to -- function as separators. CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "tokenchars=.=" "separators=X"); -- Create a table that considers space characters (codepoint 32) to be -- a token character CREATE VIRTUAL TABLE txt4 USING fts4(tokenize=unicode61 "tokenchars= ");
If a character specified as part of the argument to "tokenchars=" is considered to be a token character by default, it is ignored. This is true even if it has been marked as a separator by an earlier "separators=" option. Similarly, if a character specified as part of a "separators=" option is treated as a separator character by default, it is ignored. If multiple "tokenchars=" or "separators=" options are specified, all are processed. For example:
-- Create a table that uses the unicode61 tokenizer, but considers "."
-- and "=" characters to be part of tokens, and capital "X" characters to
-- function as separators. Both of the "tokenchars=" options are processed
-- The "separators=" option ignores the "." passed to it, as "." is by
-- default a separator character, even though it has been marked as a token
-- character by an earlier "tokenchars=" option.
CREATE VIRTUAL TABLE txt5 USING fts4(
tokenize=unicode61 "tokenchars=." "separators=X." "tokenchars=="
);
The arguments passed to the "tokenchars=" or "separators=" options are case-sensitive. In the example above, specifying that "X" is a separator character does not affect the way "x" is handled.
In addition to providing built-in "simple", "porter" and (possibly) "icu" and "unicode61" tokenizers, FTS provides an interface for applications to implement and register custom tokenizers written in C. The interface used to create a new tokenizer is defined and described in the fts3_tokenizer.h source file.
Registering a new FTS tokenizer is similar to registering a new virtual table module with SQLite. The user passes a pointer to a structure containing pointers to various callback functions that make up the implementation of the new tokenizer type. For tokenizers, the structure (defined in fts3_tokenizer.h) is called "sqlite3_tokenizer_module".
FTS does not expose a C-function that users call to register new tokenizer types with a database handle. Instead, the pointer must be encoded as an SQL blob value and passed to FTS through the SQL engine by evaluating a special scalar function, "fts3_tokenizer()". The fts3_tokenizer() function may be called with one or two arguments, as follows:
SELECT fts3_tokenizer(<tokenizer-name>); SELECT fts3_tokenizer(<tokenizer-name>, <sqlite3_tokenizer_module ptr>);
Where <tokenizer-name> is parameter to which a string is bound using sqlite3_bind_text() where the string identifies the tokenizer and <sqlite3_tokenizer_module ptr> is a parameter to which a BLOB is bound using sqlite3_bind_blob() where the value of the BLOB is a pointer to an sqlite3_tokenizer_module structure. If the second argument is present, it is registered as tokenizer <tokenizer-name> and a copy of it returned. If only one argument is passed, a pointer to the tokenizer implementation currently registered as <tokenizer-name> is returned, encoded as a blob. Or, if no such tokenizer exists, an SQL exception (error) is raised.
Prior to SQLite version 3.11.0 (2016-02-15), the arguments to fts3_tokenizer() could be literal strings or BLOBs. They did not have to be bound parameters. But that could lead to security problems in the event of an SQL injection. Hence, the legacy behavior is now disabled by default. But the old legacy behavior can be enabled, for backwards compatibility in applications that really need it, by calling sqlite3_db_config(db,SQLITE_DBCONFIG_ENABLE_FTS3_TOKENIZER,1,0).
The following block contains an example of calling the fts3_tokenizer() function from C code:
/*
** Register a tokenizer implementation with FTS3 or FTS4.
*/
int registerTokenizer(
sqlite3 *db,
char *zName,
const sqlite3_tokenizer_module *p
){
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?1, ?2)";
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
sqlite3_bind_blob(pStmt, 2, &p, sizeof(p), SQLITE_STATIC);
sqlite3_step(pStmt);
return sqlite3_finalize(pStmt);
}
/*
** Query FTS for the tokenizer implementation named zName.
*/
int queryTokenizer(
sqlite3 *db,
char *zName,
const sqlite3_tokenizer_module **pp
){
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?)";
*pp = 0;
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
if( SQLITE_ROW==sqlite3_step(pStmt) ){
if( sqlite3_column_type(pStmt, 0)==SQLITE_BLOB ){
memcpy(pp, sqlite3_column_blob(pStmt, 0), sizeof(*pp));
}
}
return sqlite3_finalize(pStmt);
}
The "fts3tokenize" virtual table can be used to directly access any tokenizer. The following SQL demonstrates how to create an instance of the fts3tokenize virtual table:
CREATE VIRTUAL TABLE tok1 USING fts3tokenize('porter');
The name of the desired tokenizer should be substituted in place of 'porter' in the example, of course. If the tokenizer requires one or more arguments, they should be separated by commas in the fts3tokenize declaration (even though they are separated by spaces in declarations of regular fts4 tables). The following creates fts4 and fts3tokenize tables that use the same tokenizer:
CREATE VIRTUAL TABLE text1 USING fts4(tokenize=icu en_AU); CREATE VIRTUAL TABLE tokens1 USING fts3tokenize(icu, en_AU); CREATE VIRTUAL TABLE text2 USING fts4(tokenize=unicode61 "tokenchars=@." "separators=123"); CREATE VIRTUAL TABLE tokens2 USING fts3tokenize(unicode61, "tokenchars=@.", "separators=123");
Once the virtual table is created, it can be queried as follows:
SELECT token, start, end, position FROM tok1 WHERE input='This is a test sentence.';
The virtual table will return one row of output for each token in the input string. The "token" column is the text of the token. The "start" and "end" columns are the byte offset to the beginning and end of the token in the original input string. The "position" column is the sequence number of the token in the original input string. There is also an "input" column which is simply a copy of the input string that is specified in the WHERE clause. Note that a constraint of the form "input=?" must appear in the WHERE clause or else the virtual table will have no input to tokenize and will return no rows. The example above generates the following output:
thi|0|4|0 is|5|7|1 a|8|9|2 test|10|14|3 sentenc|15|23|4
Notice that the tokens in the result set from the fts3tokenize virtual table have been transformed according to the rules of the tokenizer. Since this example used the "porter" tokenizer, the "This" token was converted into "thi". If the original text of the token is desired, it can be retrieved using the "start" and "end" columns with the substr() function. For example:
SELECT substr(input, start+1, end-start), token, position FROM tok1 WHERE input='This is a test sentence.';
The fts3tokenize virtual table can be used on any tokenizer, regardless of whether or not there exists an FTS3 or FTS4 table that actually uses that tokenizer.
This section describes at a high-level the way the FTS module stores its index and content in the database. It is not necessary to read or understand the material in this section in order to use FTS in an application. However, it may be useful to application developers attempting to analyze and understand FTS performance characteristics, or to developers contemplating enhancements to the existing FTS feature set.
For each FTS virtual table in a database, three to five real (non-virtual) tables are created to store the underlying data. These real tables are called "shadow tables". The real tables are named "%_content", "%_segdir", "%_segments", "%_stat", and "%_docsize", where "%" is replaced by the name of the FTS virtual table.
The leftmost column of the "%_content" table is an INTEGER PRIMARY KEY field named "docid". Following this is one column for each column of the FTS virtual table as declared by the user, named by prepending the column name supplied by the user with "cN", where N is the index of the column within the table, numbered from left to right starting with 0. Data types supplied as part of the virtual table declaration are not used as part of the %_content table declaration. For example:
-- Virtual table declaration CREATE VIRTUAL TABLE abc USING fts4(a NUMBER, b TEXT, c); -- Corresponding %_content table declaration CREATE TABLE abc_content(docid INTEGER PRIMARY KEY, c0a, c1b, c2c);
The %_content table contains the unadulterated data inserted by the user into the FTS virtual table by the user. If the user does not explicitly supply a "docid" value when inserting records, one is selected automatically by the system.
The %_stat and %_docsize tables are only created if the FTS table uses the FTS4 module, not FTS3. Furthermore, the %_docsize table is omitted if the FTS4 table is created with the "matchinfo=fts3" directive specified as part of the CREATE VIRTUAL TABLE statement. If they are created, the schema of the two tables is as follows:
CREATE TABLE %_stat( id INTEGER PRIMARY KEY, value BLOB ); CREATE TABLE %_docsize( docid INTEGER PRIMARY KEY, size BLOB );
For each row in the FTS table, the %_docsize table contains a corresponding row with the same "docid" value. The "size" field contains a blob consisting of N FTS varints, where N is the number of user-defined columns in the table. Each varint in the "size" blob is the number of tokens in the corresponding column of the associated row in the FTS table. The %_stat table always contains a single row with the "id" column set to 0. The "value" column contains a blob consisting of N+1 FTS varints, where N is again the number of user-defined columns in the FTS table. The first varint in the blob is set to the total number of rows in the FTS table. The second and subsequent varints contain the total number of tokens stored in the corresponding column for all rows of the FTS table.
The two remaining tables, %_segments and %_segdir, are used to store the full-text index. Conceptually, this index is a lookup table that maps each term (word) to the set of docid values corresponding to records in the %_content table that contain one or more occurrences of the term. To retrieve all documents that contain a specified term, the FTS module queries this index to determine the set of docid values for records that contain the term, then retrieves the required documents from the %_content table. Regardless of the schema of the FTS virtual table, the %_segments and %_segdir tables are always created as follows:
CREATE TABLE %_segments( blockid INTEGER PRIMARY KEY, -- B-tree node id block blob -- B-tree node data ); CREATE TABLE %_segdir( level INTEGER, idx INTEGER, start_block INTEGER, -- Blockid of first node in %_segments leaves_end_block INTEGER, -- Blockid of last leaf node in %_segments end_block INTEGER, -- Blockid of last node in %_segments root BLOB, -- B-tree root node PRIMARY KEY(level, idx) );
The schema depicted above is not designed to store the full-text index directly. Instead, it is used to store one or more b-tree structures. There is one b-tree for each row in the %_segdir table. The %_segdir table row contains the root node and various meta-data associated with the b-tree structure, and the %_segments table contains all other (non-root) b-tree nodes. Each b-tree is referred to as a "segment". Once it has been created, a segment b-tree is never updated (although it may be deleted altogether).
The keys used by each segment b-tree are terms (words). As well as the key, each segment b-tree entry has an associated "doclist" (document list). A doclist consists of zero or more entries, where each entry consists of:
Entries within a doclist are sorted by docid. Positions within a doclist entry are stored in ascending order.
The contents of the logical full-text index is found by merging the contents of all segment b-trees. If a term is present in more than one segment b-tree, then it maps to the union of each individual doclist. If, for a single term, the same docid occurs in more than one doclist, then only the doclist that is part of the most recently created segment b-tree is considered valid.
Multiple b-tree structures are used instead of a single b-tree to reduce the cost of inserting records into FTS tables. When a new record is inserted into an FTS table that already contains a lot of data, it is likely that many of the terms in the new record are already present in a large number of existing records. If a single b-tree were used, then large doclist structures would have to be loaded from the database, amended to include the new docid and term-offset list, then written back to the database. Using multiple b-tree tables allows this to be avoided by creating a new b-tree which can be merged with the existing b-tree (or b-trees) later on. Merging of b-tree structures can be performed as a background task, or once a certain number of separate b-tree structures have been accumulated. Of course, this scheme makes queries more expensive (as the FTS code may have to look up individual terms in more than one b-tree and merge the results), but it has been found that in practice this overhead is often negligible.
Integer values stored as part of segment b-tree nodes are encoded using the FTS varint format. This encoding is similar, but not identical, to the SQLite varint format.
An encoded FTS varint consumes between one and ten bytes of space. The number of bytes required is determined by the sign and magnitude of the integer value encoded. More accurately, the number of bytes used to store the encoded integer depends on the position of the most significant set bit in the 64-bit twos-complement representation of the integer value. Negative values always have the most significant bit set (the sign bit), and so are always stored using the full ten bytes. Positive integer values may be stored using less space.
The final byte of an encoded FTS varint has its most significant bit cleared. All preceding bytes have the most significant bit set. Data is stored in the remaining seven least significant bits of each byte. The first byte of the encoded representation contains the least significant seven bits of the encoded integer value. The second byte of the encoded representation, if it is present, contains the seven next least significant bits of the integer value, and so on. The following table contains examples of encoded integer values:
| Decimal | Hexadecimal | Encoded Representation |
|---|---|---|
| 43 | 0x000000000000002B | 0x2B |
| 200815 | 0x000000000003106F | 0xEF 0xA0 0x0C |
| -1 | 0xFFFFFFFFFFFFFFFF | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0x01 |
Segment b-trees are prefix-compressed b+-trees. There is one segment b-tree for each row in the %_segdir table (see above). The root node of the segment b-tree is stored as a blob in the "root" field of the corresponding row of the %_segdir table. All other nodes (if any exist) are stored in the "blob" column of the %_segments table. Nodes within the %_segments table are identified by the integer value in the blockid field of the corresponding row. The following table describes the fields of the %_segdir table:
| Column | Interpretation |
|---|---|
| level | Between them, the contents of the "level" and "idx" fields define the relative age of the segment b-tree. The smaller the value stored in the "level" field, the more recently the segment b-tree was created. If two segment b-trees are of the same "level", the segment with the larger value stored in the "idx" column is more recent. The PRIMARY KEY constraint on the %_segdir table prevents any two segments from having the same value for both the "level" and "idx" fields. |
| idx | See above. |
| start_block | The blockid that corresponds to the node with the smallest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. If it exists, this node is always a leaf node. |
| leaves_end_block | The blockid that corresponds to the leaf node with the largest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. |
| end_block |
This field may contain either an integer or a text field consisting of
two integers separated by a space character (unicode codepoint 0x20).
The first, or only, integer is the blockid that corresponds to the interior node with the largest blockid that belongs to this segment b-tree. Or zero if the entire segment b-tree fits on the root node. If it exists, this node is always an interior node. The second integer, if it is present, is the aggregate size of all data stored on leaf pages in bytes. If the value is negative, then the segment is the output of an unfinished incremental-merge operation, and the absolute value is current size in bytes. |
| root | Blob containing the root node of the segment b-tree. |
Apart from the root node, the nodes that make up a single segment b-tree are always stored using a contiguous sequence of blockids. Furthermore, the nodes that make up a single level of the b-tree are themselves stored as a contiguous block, in b-tree order. The contiguous sequence of blockids used to store the b-tree leaves are allocated starting with the blockid value stored in the "start_block" column of the corresponding %_segdir row, and finishing at the blockid value stored in the "leaves_end_block" field of the same row. It is therefore possible to iterate through all the leaves of a segment b-tree, in key order, by traversing the %_segments table in blockid order from "start_block" to "leaves_end_block".
The following diagram depicts the format of a segment b-tree leaf node.
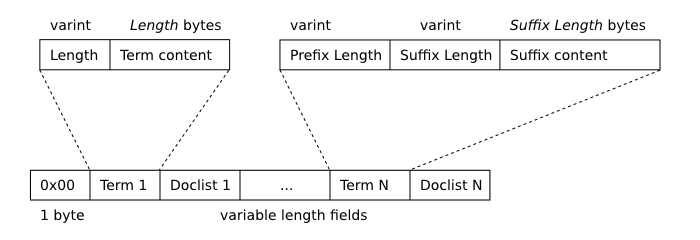
Segment B-Tree Leaf Node Format
The first term stored on each node ("Term 1" in the figure above) is stored verbatim. Each subsequent term is prefix-compressed with respect to its predecessor. Terms are stored within a page in sorted (memcmp) order.
The following diagram depicts the format of a segment b-tree interior (non-leaf) node.
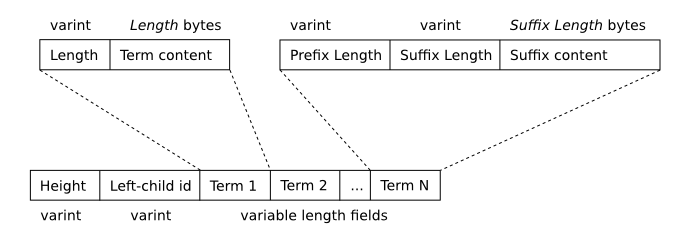
Segment B-Tree Interior Node Format
A doclist consists of an array of 64-bit signed integers, serialized using the FTS varint format. Each doclist entry is made up of a series of two or more integers, as follows:

FTS3 Doclist Format
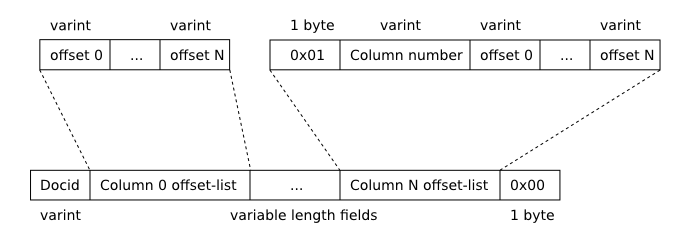
FTS Doclist Entry Format
For doclists for which the term appears in more than one column of the FTS virtual table, term-offset lists within the doclist are stored in column number order. This ensures that the term-offset list associated with column 0 (if any) is always first, allowing the first two fields of the term-offset list to be omitted in this case.
A UTF-16 byte-order-mark (BOM) is embedded at the beginning of an SQL string literal value inserted into an FTS3 table. For example:
INSERT INTO fts_table(col) VALUES(char(0xfeff)||'text...');
Malformed UTF-8 that SQLite converts to a UTF-16 byte-order-mark is embedded at the beginning of an SQL string literal value inserted into an FTS3 table.
A text value created by casting a blob that begins with the two bytes 0xFF and 0xFE, in either possible order, is inserted into an FTS3 table. For example:
INSERT INTO fts_table(col) VALUES(CAST(X'FEFF' AS TEXT));
FTS is primarily designed to support Boolean full-text queries - queries to find the set of documents that match a specified criteria. However, many (most?) search applications require that results are somehow ranked in order of "relevance", where "relevance" is defined as the likelihood that the user who performed the search is interested in a specific element of the returned set of documents. When using a search engine to find documents on the world wide web, the user expects that the most useful, or "relevant", documents will be returned as the first page of results, and that each subsequent page contains progressively less relevant results. Exactly how a machine can determine document relevance based on a users query is a complicated problem and the subject of much ongoing research.
One very simple scheme might be to count the number of instances of the users search terms in each result document. Those documents that contain many instances of the terms are considered more relevant than those with a small number of instances of each term. In an FTS application, the number of term instances in each result could be determined by counting the number of integers in the return value of the offsets function. The following example shows a query that could be used to obtain the ten most relevant results for a query entered by the user:
-- This example (and all others in this section) assumes the following schema CREATE VIRTUAL TABLE documents USING fts3(title, content); -- Assuming the application has supplied an SQLite user function named "countintegers" -- that returns the number of space-separated integers contained in its only argument, -- the following query could be used to return the titles of the 10 documents that contain -- the greatest number of instances of the users query terms. Hopefully, these 10 -- documents will be those that the users considers more or less the most "relevant". SELECT title FROM documents WHERE documents MATCH <query> ORDER BY countintegers(offsets(documents)) DESC LIMIT 10 OFFSET 0
The query above could be made to run faster by using the FTS matchinfo function to determine the number of query term instances that appear in each result. The matchinfo function is much more efficient than the offsets function. Furthermore, the matchinfo function provides extra information regarding the overall number of occurrences of each query term in the entire document set (not just the current row) and the number of documents in which each query term appears. This may be used (for example) to attach a higher weight to less common terms which may increase the overall computed relevancy of those results the user considers more interesting.
-- If the application supplies an SQLite user function called "rank" that -- interprets the blob of data returned by matchinfo and returns a numeric -- relevancy based on it, then the following SQL may be used to return the -- titles of the 10 most relevant documents in the dataset for a users query. SELECT title FROM documents WHERE documents MATCH <query> ORDER BY rank(matchinfo(documents)) DESC LIMIT 10 OFFSET 0
The SQL query in the example above uses less CPU than the first example in this section, but still has a non-obvious performance problem. SQLite satisfies this query by retrieving the value of the "title" column and matchinfo data from the FTS module for every row matched by the users query before it sorts and limits the results. Because of the way SQLite's virtual table interface works, retrieving the value of the "title" column requires loading the entire row from disk (including the "content" field, which may be quite large). This means that if the users query matches several thousand documents, many megabytes of "title" and "content" data may be loaded from disk into memory even though they will never be used for any purpose.
The SQL query in the following example block is one solution to this problem. In SQLite, when a sub-query used in a join contains a LIMIT clause, the results of the sub-query are calculated and stored in temporary table before the main query is executed. This means that SQLite will load only the docid and matchinfo data for each row matching the users query into memory, determine the docid values corresponding to the ten most relevant documents, then load only the title and content information for those 10 documents only. Because both the matchinfo and docid values are gleaned entirely from the full-text index, this results in dramatically less data being loaded from the database into memory.
SELECT title FROM documents JOIN (
SELECT docid, rank(matchinfo(documents)) AS rank
FROM documents
WHERE documents MATCH <query>
ORDER BY rank DESC
LIMIT 10 OFFSET 0
) AS ranktable USING(docid)
ORDER BY ranktable.rank DESC
The next block of SQL enhances the query with solutions to two other problems that may arise in developing search applications using FTS:
The snippet function cannot be used with the above query. Because the outer query does not include a "WHERE ... MATCH" clause, the snippet function may not be used with it. One solution is to duplicate the WHERE clause used by the sub-query in the outer query. The overhead associated with this is usually negligible.
The relevancy of a document may depend on something other than just the data available in the return value of matchinfo. For example each document in the database may be assigned a static weight based on factors unrelated to its content (origin, author, age, number of references etc.). These values can be stored by the application in a separate table that can be joined against the documents table in the sub-query so that the rank function may access them.
This version of the query is very similar to that used by the sqlite.org documentation search application.
-- This table stores the static weight assigned to each document in FTS table
-- "documents". For each row in the documents table there is a corresponding row
-- with the same docid value in this table.
CREATE TABLE documents_data(docid INTEGER PRIMARY KEY, weight);
-- This query is similar to the one in the block above, except that:
--
-- 1. It returns a "snippet" of text along with the document title for display. So
-- that the snippet function may be used, the "WHERE ... MATCH ..." clause from
-- the sub-query is duplicated in the outer query.
--
-- 2. The sub-query joins the documents table with the document_data table, so that
-- implementation of the rank function has access to the static weight assigned
-- to each document.
SELECT title, snippet(documents) FROM documents JOIN (
SELECT docid, rank(matchinfo(documents), documents_data.weight) AS rank
FROM documents JOIN documents_data USING(docid)
WHERE documents MATCH <query>
ORDER BY rank DESC
LIMIT 10 OFFSET 0
) AS ranktable USING(docid)
WHERE documents MATCH <query>
ORDER BY ranktable.rank DESC
All the example queries above return the ten most relevant query results. By modifying the values used with the OFFSET and LIMIT clauses, a query to return (say) the next ten most relevant results is easy to construct. This may be used to obtain the data required for a search applications second and subsequent pages of results.
The next block contains an example rank function that uses matchinfo data implemented in C. Instead of a single weight, it allows a weight to be externally assigned to each column of each document. It may be registered with SQLite like any other user function using sqlite3_create_function.
Security Warning: Because it is just an ordinary SQL function, rank() may be invoked as part of any SQL query in any context. This means that the first argument passed may not be a valid matchinfo blob. Implementors should take care to handle this case without causing buffer overruns or other potential security problems.
/*
** SQLite user defined function to use with matchinfo() to calculate the
** relevancy of an FTS match. The value returned is the relevancy score
** (a real value greater than or equal to zero). A larger value indicates
** a more relevant document.
**
** The overall relevancy returned is the sum of the relevancies of each
** column value in the FTS table. The relevancy of a column value is the
** sum of the following for each reportable phrase in the FTS query:
**
** (<hit count> / <global hit count>) * <column weight>
**
** where <hit count> is the number of instances of the phrase in the
** column value of the current row and <global hit count> is the number
** of instances of the phrase in the same column of all rows in the FTS
** table. The <column weight> is a weighting factor assigned to each
** column by the caller (see below).
**
** The first argument to this function must be the return value of the FTS
** matchinfo() function. Following this must be one argument for each column
** of the FTS table containing a numeric weight factor for the corresponding
** column. Example:
**
** CREATE VIRTUAL TABLE documents USING fts3(title, content)
**
** The following query returns the docids of documents that match the full-text
** query <query> sorted from most to least relevant. When calculating
** relevance, query term instances in the 'title' column are given twice the
** weighting of those in the 'content' column.
**
** SELECT docid FROM documents
** WHERE documents MATCH <query>
** ORDER BY rank(matchinfo(documents), 1.0, 0.5) DESC
*/
static void rankfunc(sqlite3_context *pCtx, int nVal, sqlite3_value **apVal){
int *aMatchinfo; /* Return value of matchinfo() */
int nMatchinfo; /* Number of elements in aMatchinfo[] */
int nCol = 0; /* Number of columns in the table */
int nPhrase = 0; /* Number of phrases in the query */
int iPhrase; /* Current phrase */
double score = 0.0; /* Value to return */
assert( sizeof(int)==4 );
/* Check that the number of arguments passed to this function is correct.
** If not, jump to wrong_number_args. Set aMatchinfo to point to the array
** of unsigned integer values returned by FTS function matchinfo. Set
** nPhrase to contain the number of reportable phrases in the users full-text
** query, and nCol to the number of columns in the table. Then check that the
** size of the matchinfo blob is as expected. Return an error if it is not.
*/
if( nVal<1 ) goto wrong_number_args;
aMatchinfo = (unsigned int *)sqlite3_value_blob(apVal[0]);
nMatchinfo = sqlite3_value_bytes(apVal[0]) / sizeof(int);
if( nMatchinfo>=2 ){
nPhrase = aMatchinfo[0];
nCol = aMatchinfo[1];
}
if( nMatchinfo!=(2+3*nCol*nPhrase) ){
sqlite3_result_error(pCtx,
"invalid matchinfo blob passed to function rank()", -1);
return;
}
if( nVal!=(1+nCol) ) goto wrong_number_args;
/* Iterate through each phrase in the users query. */
for(iPhrase=0; iPhrase<nPhrase; iPhrase++){
int iCol; /* Current column */
/* Now iterate through each column in the users query. For each column,
** increment the relevancy score by:
**
** (<hit count> / <global hit count>) * <column weight>
**
** aPhraseinfo[] points to the start of the data for phrase iPhrase. So
** the hit count and global hit counts for each column are found in
** aPhraseinfo[iCol*3] and aPhraseinfo[iCol*3+1], respectively.
*/
int *aPhraseinfo = &aMatchinfo[2 + iPhrase*nCol*3];
for(iCol=0; iCol<nCol; iCol++){
int nHitCount = aPhraseinfo[3*iCol];
int nGlobalHitCount = aPhraseinfo[3*iCol+1];
double weight = sqlite3_value_double(apVal[iCol+1]);
if( nHitCount>0 ){
score += ((double)nHitCount / (double)nGlobalHitCount) * weight;
}
}
}
sqlite3_result_double(pCtx, score);
return;
/* Jump here if the wrong number of arguments are passed to this function */
wrong_number_args:
sqlite3_result_error(pCtx, "wrong number of arguments to function rank()", -1);
}
此頁面最後修改於 2023-10-10 17:29:48 UTC